

本系列代码托管于:https://github.com/chintsan-code/cuda_by_example
本篇使用的项目为:heat_notexture、heat
纹理内存(Texture Memory)和常量内存一样,属于只读内存。之所以被称为”纹理”,是因为最初是为图形应用设计的。与常量内存类似的是,纹理内存同样缓存在芯片上,因此在某些情况下,它能够减少对内存的请求并提供更高效的内存带宽。
纹理缓存是专门为那些在内存访问模式中存在大量空间局部性(Spatial Locality)的图形应用程序而设计的,这意味着一个线程读取的位置可能与邻近线程读取的位置”非常接近”:
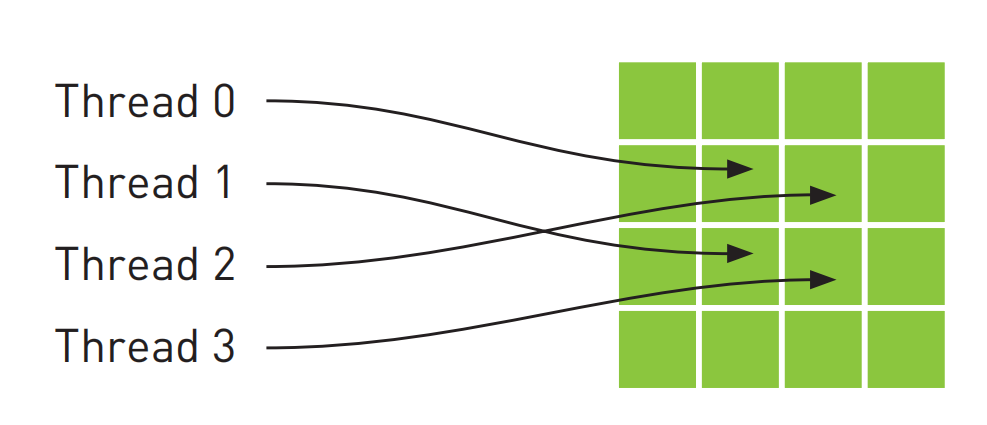
从数学的角度,上图中的4个地址并非连续的(内存地址可以看做一维),在一般的CPU缓存中,这些地址将不会缓存。
但由于GPU纹理缓存是专门为了加速这种访问模式而设计的,因此如果在这种情况中使用纹理内存而不是全局内存,那么将会获得性能的提升。
一. 不使用纹理内存的热传导模拟
假设有这个一个房间,将其分成一个个的网格,在网格中随机散布一些”热源”,它们有着不同的固定温度(之所以要固定,是为了简化这个问题)
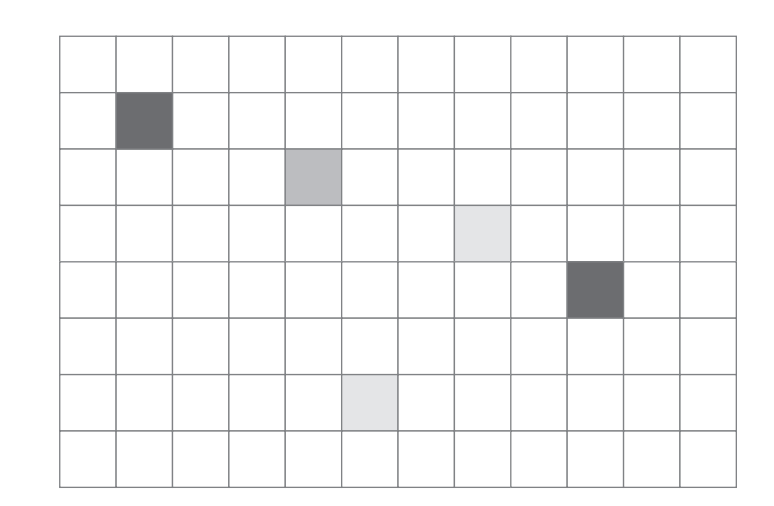
接着我们要计算随着时间的推移,热量在这个房间中的扩散情况。热量会在某个单元及其邻近单元之间”流动”,如果某个单元的邻近单元的温度更高,那么它将变冷:
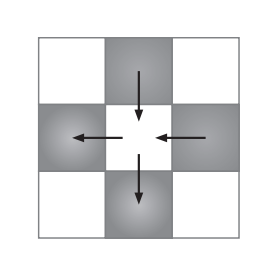
在热传导模型中,我们对单元中新温度的计算方法为:将单元与邻近单元的温度相加起来,然后减去原有的温度:
$$T_{NEW}=T_{OLD}+\sum_{NEIGHBOR}{k(T_{NEIGHBOR}-T_{OLD})}$$
其中\(k\)表示模拟过程中热量的流动速率,\(k\)值越大,表示系统会更快地达到稳定温度。由于这里只考虑上、下、左、右4个邻近单元,并且等式中的\(k\)和\(T_{OLD}\)都是常数,因此可以将上面的等式展开为:
$$T_{NEW}=T_{OLD}+k(T_{TOP}+T_{BOTTOM}+T_{LEFT}+T_{RIGHT}-4T_{OLD})$$
下面是完整代码:
// heat_notexture
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
#include "../../common/cpu_anim.h"
#define DIM 1024
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
__global__ void copy_const_kernel(float* iptr, const float* cptr) {
// 将threadIdx/BlockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
// 当温度不为0时,才会执行复制。这是为了维持非热源单位在上一次计算得到的温度值
if (cptr[offset] != 0)
iptr[offset] = cptr[offset];
}
__global__ void blend_kernel(float* outSrc, const float* inSrc) {
// 将threadIdx/BlockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
// 每个Thread都负责计算一个单元(一个像素):读取对应单元及其相邻单元的温度值,
// 然后执行更新运算,将得到的新值更新到对应的单元。
int left = offset - 1;
int right = offset + 1;
if (x == 0)
left++; // 边缘处理,下同
if (x == DIM - 1)
right--;
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0)
top += DIM;
if (y == DIM - 1)
bottom -= DIM;
// 更新公式:T_new = T_old + k * sum(T_neighbor - T_old)
outSrc[offset] = inSrc[offset] + SPEED * (inSrc[left] + inSrc[right]
+ inSrc[top] + inSrc[bottom]
- inSrc[offset] * 4);
}
// 更新函数中需要的全局变量
struct DataBlock{
unsigned char* dev_bitmap;
float* dev_inSrc; // 输入缓冲区
float* dev_outSrc; // 输出缓冲区
float* dev_constSrc; // 初始化的热源
CPUAnimBitmap* bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
// 每一帧动画将调用anim_gpu()
void anim_gpu(DataBlock* data, int ticks) {
HANDLE_ERROR(cudaEventRecord(data->start, 0));
// 每个Block有(16, 16)个Thread,(DIM/16, DIM/16)组织成一个Grid
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
CPUAnimBitmap* bitmap = data->bitmap;
// 每一帧动画都经过了90轮迭代计算,可以修改这个值
for (int i = 0; i < 90; i++) {
// 为了简单,热源单元本身的温度将保持不变。但是,热量可以从更热的单元传导到更冷的单元
copy_const_kernel<<<blocks, threads>>>(data->dev_inSrc, data->dev_constSrc);
// 更新每一个单元
blend_kernel<<<blocks, threads>>>(data->dev_outSrc, data->dev_inSrc);
// 交换输出和输入,将本次计算的输出作为下次计算的输入
swap(data->dev_inSrc, data->dev_outSrc);
}
// 将温度转为颜色
float_to_color<<<blocks, threads>>>(data->dev_bitmap, data->dev_inSrc);
// 将结果复制回CPU
HANDLE_ERROR(cudaMemcpy(bitmap->get_ptr(),
data->dev_bitmap,
bitmap->image_size(),
cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaEventRecord(data->stop, 0));
HANDLE_ERROR(cudaEventSynchronize(data->stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, data->start, data->stop)); // 计算每一帧动画需要的时间
data->totalTime += elapsedTime;
data->frames++;
printf("Average Time per frame: %3.1f ms\n", data->totalTime / data->frames);
}
void anim_exit(DataBlock* data) {
HANDLE_ERROR(cudaFree(data->dev_inSrc));
HANDLE_ERROR(cudaFree(data->dev_outSrc));
HANDLE_ERROR(cudaFree(data->dev_constSrc));
HANDLE_ERROR(cudaEventDestroy(data->start));
HANDLE_ERROR(cudaEventDestroy(data->stop));
}
int main() {
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
HANDLE_ERROR(cudaEventCreate(&data.start));
HANDLE_ERROR(cudaEventCreate(&data.stop));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_bitmap, bitmap.image_size()));
// 假设float类型的大小为4个字符(即rgba)
HANDLE_ERROR(cudaMalloc((void**)&data.dev_inSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_outSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_constSrc, bitmap.image_size()));
float* temp = (float*)malloc(bitmap.image_size());
// 下面加入一些热源
for (int i = 0; i < DIM*DIM; i++) {
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x > 300) && (x < 600) && (y > 310) && (y < 601))
temp[i] = MAX_TEMP;
}
temp[DIM * 100 + 100] = (MAX_TEMP + MIN_TEMP) / 2;
temp[DIM * 700 + 100] = MIN_TEMP;
temp[DIM * 300 + 300] = MIN_TEMP;
temp[DIM * 200 + 700] = MIN_TEMP;
for (int y = 800; y < 900; y++) {
for (int x = 400; x < 500; x++) {
temp[x + y * DIM] = MIN_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_constSrc,
temp,
bitmap.image_size(),
cudaMemcpyHostToDevice));
for (int y = 800; y < DIM; y++) {
for (int x = 0; x < 200; x++) {
temp[x + y * DIM] = MAX_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_inSrc,
temp,
bitmap.image_size(),
cudaMemcpyHostToDevice));
free(temp);
// 每次需要生成一帧图像,就调用一次anim_gpu,之后再调用anim_exit将分配的显存释放掉
bitmap.anim_and_exit((void (*)(void*, int))anim_gpu,
(void (*)(void*))anim_exit);
return 0;
}其主要过程为:
(1)给定一个包含初始热源的网格,并让这些热源一直处于”恒温”,此步骤是通过copy_const_kernel()实现的。
(2)跟进上面的公式计算输出温度网格,此步骤是通过blend_kernel()实现的。
(3)交换输入和输出,重复90次,代表每一帧动画都经过了90次迭代计算。可以修改这个迭代次数。迭代次数越小,生成动画的速度越快,但是系统达到稳定的时间也需要更久。
二. 使用纹理内存的热传导模拟
由于在上面的情景下,单元的温度的更新与邻近单元的温度有关系,也就是说,在温度更新计算的内存访问模式中存在巨大的内存空间局部性,因此可以使用纹理内存来加速。
首先,需要将输入数据声明为texture类型的引用,并且必须声明为全局变量。这里使用float类型,因为温度数值是浮点型的:
texture<float> texConstSrc;
texture<float> texIn;
texture<float> texOut;注意,IDE可能会提示语法错误,不用理会,这是IDE没有识别出来,不影响编译。
接着,需要将这三个变量绑定到内存缓冲区:
HANDLE_ERROR(cudaBindTexture(NULL, texConstSrc, data.dev_constSrc, bitmap.image_size()));
HANDLE_ERROR(cudaBindTexture(NULL, texIn, data.dev_inSrc, bitmap.image_size()));
HANDLE_ERROR(cudaBindTexture(NULL, texOut, data.dev_outSrc, bitmap.image_size()));这相当于告诉CUDA Runtime:
- 我们希望将指定的缓冲区作为纹理内存使用
- 我们希望将纹理引用作为纹理的”名字”
主函数部分已经修改完成。接着修改核函数部分。
在未使用纹理内存时,我们通过下标的方式访问全局内存:
if (cptr[offset] != 0)
iptr[offset] = cptr[offset];现在,使用了纹理内存,当需要读取其中的数据时,需要通过特殊的函数来告诉GPU将读取请求转发到纹理内存而不是标准的全局内存。因此当读取内存时不再使用方括号[]和下标从缓冲区中读取,而是改为使用tex1Dfetch():
float center = tex1Dfetch(texConstSrc, offset);
if (center != 0)
iptr[offset] = center;虽然tex1Dfetch()看上去像一个函数,但其实是一个编译器内置函数(Intrinsic)。由于纹理引用必须声明为全局变量,因此就不能再通过将输入缓冲区和输出缓冲区作为参数传递给blend_kernel()了,因为编译器需要在编译时知道tex1Dfetch()应该对哪些纹理采样。现在通过一个bool变量dstOut传递给blend_kernel(),这个标识会告诉我们使用哪个缓冲区作为输入或输出。下面是对blend_kernel()的修改:
__global__ void blend_kernel(float* dst, bool dstOut) {
// 将threadIdx/BlockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
// 每个Thread都负责计算一个单元(一个像素):读取对应单元及其相邻单元的温度值,
// 然后执行更新运算,将得到的新值更新到对应的单元。
int left = offset - 1;
int right = offset + 1;
if (x == 0)
left++; // 边缘处理,下同
if (x == DIM - 1)
right--;
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0)
top += DIM;
if (y == DIM - 1)
bottom -= DIM;
float t, l, c, r, b;
if (dstOut) {
t = tex1Dfetch(texIn, top); // top
l = tex1Dfetch(texIn, left); // left
c = tex1Dfetch(texIn, offset); // center
r = tex1Dfetch(texIn, right); // right
b = tex1Dfetch(texIn, bottom); // bottom
}
else {
t = tex1Dfetch(texOut, top);
l = tex1Dfetch(texOut, left);
c = tex1Dfetch(texOut, offset);
r = tex1Dfetch(texOut, right);
b = tex1Dfetch(texOut, bottom);
}
// 更新公式:T_new = T_old + k * sum(T_neighbor - T_old)
dst[offset] = c + SPEED * (t + b + l + r - 4 * c);
}这个标识dstOut会在anim_gpu()中进行修改,以达到交换输入和输出缓存区的效果:
dstOut = !dstOut;最后,需要取消对纹理内存的绑定:
cudaUnbindTexture(texConstSrc);
cudaUnbindTexture(texIn);
cudaUnbindTexture(texOut);完整代码如下:
// heat
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
#include "../../common/cpu_anim.h"
#define DIM 1024
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
// 声明纹理引用,这些变量将位于GPU上
texture<float> texConstSrc;
texture<float> texIn;
texture<float> texOut;
__global__ void copy_const_kernel(float* iptr) {
// 将threadIdx/BlockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
// 当温度不为0时,才会执行复制。这是为了维持非热源单位在上一次计算得到的温度值
float center = tex1Dfetch(texConstSrc, offset);
if (center != 0)
iptr[offset] = center;
}
__global__ void blend_kernel(float* dst, bool dstOut) {
// 将threadIdx/BlockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
// 每个Thread都负责计算一个单元(一个像素):读取对应单元及其相邻单元的温度值,
// 然后执行更新运算,将得到的新值更新到对应的单元。
int left = offset - 1;
int right = offset + 1;
if (x == 0)
left++; // 边缘处理,下同
if (x == DIM - 1)
right--;
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0)
top += DIM;
if (y == DIM - 1)
bottom -= DIM;
float t, l, c, r, b;
if (dstOut) {
t = tex1Dfetch(texIn, top); // top
l = tex1Dfetch(texIn, left); // left
c = tex1Dfetch(texIn, offset); // center
r = tex1Dfetch(texIn, right); // right
b = tex1Dfetch(texIn, bottom); // bottom
}
else {
t = tex1Dfetch(texOut, top);
l = tex1Dfetch(texOut, left);
c = tex1Dfetch(texOut, offset);
r = tex1Dfetch(texOut, right);
b = tex1Dfetch(texOut, bottom);
}
// 更新公式:T_new = T_old + k * sum(T_neighbor - T_old)
dst[offset] = c + SPEED * (t + b + l + r - 4 * c);
}
// 更新函数中需要的全局变量
struct DataBlock
{
unsigned char* dev_bitmap;
float* dev_inSrc; // 输入缓冲区
float* dev_outSrc; // 输出缓冲区
float* dev_constSrc; // 初始化的热源
CPUAnimBitmap* bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
// 每一帧动画将调用anim_gpu()
void anim_gpu(DataBlock* data, int ticks) {
HANDLE_ERROR(cudaEventRecord(data->start, 0));
// 每个Block有(16, 16)个Thread,(DIM/16, DIM/16)组织成一个Grid
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
CPUAnimBitmap* bitmap = data->bitmap;
// 每一帧动画都经过了90轮迭代计算,可以修改这个值
// 由于tex是全局并且是有界的,因此需要通过一个标识来选择
// 每次迭代中哪个是输入/输出
volatile bool dstOut = true;
for (int i = 0; i < 90; i++) {
float *in, *out;
if (dstOut) {
in = data->dev_inSrc;
out = data->dev_outSrc;
}
else {
in = data->dev_outSrc;
out = data->dev_inSrc;
}
// 为了简单,热源单元本身的温度将保持不变。但是,热量可以从更热的单元传导到更冷的单元
copy_const_kernel<<<blocks, threads>>>(in);
// 更新每一个单元
blend_kernel<<<blocks, threads>>>(out, dstOut);
// 交换输出和输入,将本次计算的输出作为下次计算的输入
dstOut = !dstOut;
}
// 将温度转为颜色
float_to_color<<<blocks, threads>>>(data->dev_bitmap, data->dev_inSrc);
// 将结果复制回CPU
HANDLE_ERROR(cudaMemcpy(bitmap->get_ptr(),
data->dev_bitmap,
bitmap->image_size(),
cudaMemcpyDeviceToHost));
HANDLE_ERROR(cudaEventRecord(data->stop, 0));
HANDLE_ERROR(cudaEventSynchronize(data->stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, data->start, data->stop)); // 计算每一帧动画需要的时间
data->totalTime += elapsedTime;
data->frames++;
printf("Average Time per frame: %3.1f ms\n", data->totalTime / data->frames);
}
void anim_exit(DataBlock* data) {
// 取消纹理内存的绑定
HANDLE_ERROR(cudaUnbindTexture(texConstSrc));
HANDLE_ERROR(cudaUnbindTexture(texIn));
HANDLE_ERROR(cudaUnbindTexture(texOut));
HANDLE_ERROR(cudaFree(data->dev_inSrc));
HANDLE_ERROR(cudaFree(data->dev_outSrc));
HANDLE_ERROR(cudaFree(data->dev_constSrc));
HANDLE_ERROR(cudaEventDestroy(data->start));
HANDLE_ERROR(cudaEventDestroy(data->stop));
}
int main() {
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
HANDLE_ERROR(cudaEventCreate(&data.start));
HANDLE_ERROR(cudaEventCreate(&data.stop));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_bitmap, bitmap.image_size()));
// 假设float类型的大小为4个字符(即rgba)
HANDLE_ERROR(cudaMalloc((void**)&data.dev_inSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_outSrc, bitmap.image_size()));
HANDLE_ERROR(cudaMalloc((void**)&data.dev_constSrc, bitmap.image_size()));
// 将三个内存绑定到之前声明的纹理应用
HANDLE_ERROR(cudaBindTexture(NULL, texConstSrc, data.dev_constSrc, bitmap.image_size()));
HANDLE_ERROR(cudaBindTexture(NULL, texIn, data.dev_inSrc, bitmap.image_size()));
HANDLE_ERROR(cudaBindTexture(NULL, texOut, data.dev_outSrc, bitmap.image_size()));
float* temp = (float*)malloc(bitmap.image_size());
// 下面加入一些热源
for (int i = 0; i < DIM * DIM; i++) {
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x > 300) && (x < 600) && (y > 310) && (y < 601))
temp[i] = MAX_TEMP;
}
temp[DIM * 100 + 100] = (MAX_TEMP + MIN_TEMP) / 2;
temp[DIM * 700 + 100] = MIN_TEMP;
temp[DIM * 300 + 300] = MIN_TEMP;
temp[DIM * 200 + 700] = MIN_TEMP;
for (int y = 800; y < 900; y++) {
for (int x = 400; x < 500; x++) {
temp[x + y * DIM] = MIN_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_constSrc,
temp,
bitmap.image_size(),
cudaMemcpyHostToDevice));
for (int y = 800; y < DIM; y++) {
for (int x = 0; x < 200; x++) {
temp[x + y * DIM] = MAX_TEMP;
}
}
HANDLE_ERROR(cudaMemcpy(data.dev_inSrc,
temp,
bitmap.image_size(),
cudaMemcpyHostToDevice));
free(temp);
// 每次需要生成一帧图像,就调用一次anim_gpu,之后再调用anim_exit将分配的显存释放掉
bitmap.anim_and_exit((void (*)(void*, int))anim_gpu,
(void (*)(void*))anim_exit);
return 0;
}参考:
- 《GPU高性能编程 CUDA实战》








评论 (0)