

本系列代码托管于:https://github.com/chintsan-code/cuda_by_example
本篇使用的项目为:ray_tracing_noconst、ray_tracing_const
GPU中包含大量的数学计算单元,通常在上面进行通用计算的瓶颈并不在芯片的数学计算吞吐量,而是芯片的内存带宽。由于在图像处理器上包含了非常多的数学逻辑单元(ALU),因此有时输入数据的速率甚至无法维持如此高的计算速率。因此,有必要研究一些手段来减少计算问题时的内存通信量。
在之前,我们已经看到CUDA C程序中可以使用全局内存和共享内存。但是CUDA C还支持另一种类型的内存,即常量内存,从它的名字可以看出,常量内存用于保存在核函数执行期间不会发生变化额数据。CUDA对常量内存采取了不同于标准全局内存额处理方式,在某些情况下,用常量内存替换全局内存能有效地减少内存带宽。
一. 光线跟踪介绍
这是一个光线跟踪(Ray Tracing)程序。对于什么是光线跟踪并不是此次的重点,只需要简单地知道,光线跟踪是从三维对象场景中生成二维图像的一种方式。它的实现原理很简单:在场景中选择一个位置放置一台假想的相机。这台数字相机包含一个光传感器来生成图像,因此我们需要判断哪些光线将接触到这个传感器。图像中的每个像素与命中传感器的光线有着相同的颜色和强度。
可以使用逆向的计算方式:不是找出哪些光线将会命中某个像素,而是想象从该像素发射了一道光线进入场景。按这个思路,每个像素的行为都想一只“观察”场景的眼睛。下图说明了这些像素投射光线并进入场景的过程。
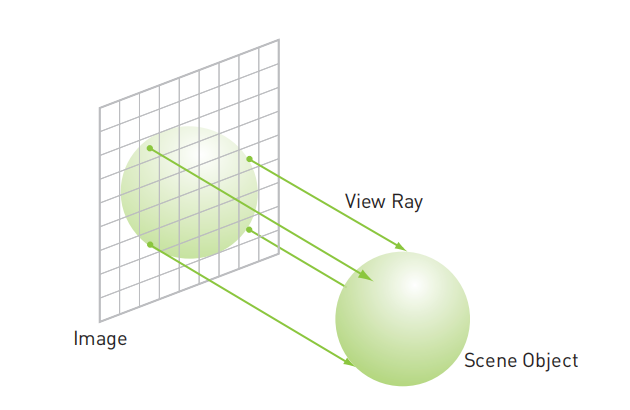
想象一下,从像素中射出跟踪光线(View Ray),直到光线命中某个对象(场景目标 Scene Object),然后计算这个像素的颜色。
在更复杂的光线跟踪模型中,场景中的反光物体能够反射光线,而半透明的物体能够折射光线。这将产生二次射线(Secondary Ray)和三次射线(Tertiary Ray)等等。这里我们只实现基本的光线跟踪器,它只支持一组包含球状物体的场景,并且相机被固定在Z轴,面向原点。此外,我们将不支持场景中的任何照明,从而避免二次光线带来的复杂性。我们也不计算照明效果,而只是为球面分配一个颜色值,然后如果它们是可见的,则通过某个预先计算的值对其着色。
二. 不使用常量内存编写光线跟踪
首先编写一个使用标准全局内存的CUDA程序:
// ray_tracing_noconst
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <math.h>
#include "../../common/book.h"
#include "../../common/cpu_bitmap.h"
#define INF 2e10f
#define rnd( x ) (x * rand() / RAND_MAX)
#define DIM 1024
#define SPHERES 20
struct Sphere
{
float r, g, b; // 球面的颜色
float radius; // 球面半径
float x, y, z; // 球面的中心坐标(x,y,z)
// 对于来自(ox,oy)处的光线,计算是否会与这个球面相交,
// 如果相交,计算从相机到光线命中球面处的距离
__device__ float hit(float ox, float oy, float* n) {
float dx = ox - x;
float dy = oy - y;
// 判断直线与球面相交的情况
if (dx * dx + dy * dy < radius * radius) {
float dz = sqrtf(radius * radius - dx * dx - dy * dy);
*n = dz / sqrtf(radius * radius);
return dz + z;
}
return -INF;
}
};
__global__ void kernel(Sphere* s, unsigned char* ptr) {
// 将threadIdx/blockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
// 将图像坐标(x, y)偏移DIM/2,这样z轴将穿过图像的中心
float ox = (x - DIM / 2);
float oy = (y - DIM / 2);
// 每条光线都需要判断与球面相交的情况,使用迭代的方式调用hit方法判断
float r = 0, g = 0, b = 0;
float maxz = -INF;
for (int i = 0; i < SPHERES; i++) {
float n;
float t = s[i].hit(ox, oy, &n);
// 如果光线命中了当前当前的球面,那么接着判断命中位置与相机之间的距离是否比上一次命中的距离更加解决。
// 如果更加接近,那么将这个距离保存为新的最接近球面,保存这个球面的rgb颜色值,
// 当这个循环结束时,当前线程就会知道与相机最接近的球面的颜色。
// 如果没有命中,则rgb为初始值(0,0,0)
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset * 4 + 0] = (int)(r * 255);
ptr[offset * 4 + 1] = (int)(g * 255);
ptr[offset * 4 + 2] = (int)(b * 255);
ptr[offset * 4 + 3] = 255;
}
int main() {
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_ptr;
Sphere* dev_s;
// 在GPU上分配内存以计算输出位图
HANDLE_ERROR(cudaMalloc((void**)&dev_ptr, bitmap.image_size()));
// 为Sphere数据集分配内存
HANDLE_ERROR(cudaMalloc((void**)&dev_s, SPHERES * sizeof(Sphere)));
// 分配临时内存,对其初始化,并复制到GPU上的内存,然后再释放临时内存
Sphere* spheres = (Sphere*)malloc(SPHERES * sizeof(Sphere));
// 生成SPHERES个随机球面
for (int i = 0; i < SPHERES; i++) {
spheres[i].r = rnd(1.0f);
spheres[i].g = rnd(1.0f);
spheres[i].b = rnd(1.0f);
spheres[i].x = rnd(1000.0f) - 500;
spheres[i].y = rnd(1000.0f) - 500;
spheres[i].z = rnd(1000.0f) - 500;
spheres[i].radius = rnd(100.0f) + 20;
}
HANDLE_ERROR(cudaMemcpy(dev_s, spheres, SPHERES * sizeof(Sphere), cudaMemcpyHostToDevice));
free(spheres); // 复制到GPU后就可以释放临时缓冲区了
// 从球面数据中生成一张bitmap
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel<<<blocks, threads>>>(dev_s, dev_ptr);
// 将bitmap从GPU复制回CPU以显示
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_ptr,
bitmap.image_size(),
cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
// 释放内存
HANDLE_ERROR(cudaFree(dev_s));
HANDLE_ERROR(cudaFree(dev_ptr));
return 0;
}首先定义了一个球面的数据结构,其中包含球面的中心坐标(x,y,z),半径radius,以及颜色(r,g,b)。
struct Sphere
{
float r, g, b; // 球面的颜色
float radius; // 球面半径
float x, y, z; // 球面的中心坐标(x,y,z)
// 对于来自(ox,oy)处的光线,计算是否会与这个球面相交,
// 如果相交,计算从相机到光线命中球面处的距离
__device__ float hit(float ox, float oy, float* n) {
float dx = ox - x;
float dy = oy - y;
// 判断直线与球面相交的情况
if (dx * dx + dy * dy < radius * radius) {
float dz = sqrtf(radius * radius - dx * dx - dy * dy);
*n = dz / sqrtf(radius * radius);
return dz + z;
}
return -INF;
}
};hit方法用来计算来自(ox,oy)处的光线是否会与这个球面相交,如果相交,计算从相机到光线命中球面处的距离。判断方法应该是使用了直线与球面相切的公式,看不懂,不过不是重点,可以跳过。
最后来看核函数,看注释即可:
__global__ void kernel(Sphere* s, unsigned char* ptr) {
// 将threadIdx/blockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
// 将图像坐标(x, y)偏移DIM/2,这样z轴将穿过图像的中心
float ox = (x - DIM / 2);
float oy = (y - DIM / 2);
// 每条光线都需要判断与球面相交的情况,使用迭代的方式调用hit方法判断
float r = 0, g = 0, b = 0;
float maxz = -INF;
for (int i = 0; i < SPHERES; i++) {
float n;
float t = s[i].hit(ox, oy, &n);
// 如果光线命中了当前当前的球面,那么接着判断命中位置与相机之间的距离是否比上一次命中的距离更加解决。
// 如果更加接近,那么将这个距离保存为新的最接近球面,保存这个球面的rgb颜色值,
// 当这个循环结束时,当前线程就会知道与相机最接近的球面的颜色。
// 如果没有命中,则rgb为初始值(0,0,0)
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset * 4 + 0] = (int)(r * 255);
ptr[offset * 4 + 1] = (int)(g * 255);
ptr[offset * 4 + 2] = (int)(b * 255);
ptr[offset * 4 + 3] = 255;
}程序执行的效果如下:

三. 通过常量内存来实现光线跟踪
在上面的程序中,花了比较大的篇幅介绍光线跟踪,但这并不是本节的重点。现在,使用常量内存来改进这个示例。由于常量内存是不能修改的,因此显然无法用常量内存来保存输出图像的数据。在这个示例中只有一个输入数据,即球面数据,因此应该将这个数据保存到常量内存中。
使用方法是在变量前加上__constant__关键字:
__constant__ Sphere dev_s[SPHERES];
在之前,我们是声明了一个指针Sphere* dev_s,然后使用cudaMalloc()来为这个指针分配GPU内存。现在我们将其改为了常量内存,需要修改为静态分配内存空间,也就是在编译时为这个数组提交一个固定的大小,而且之后也不再需要使用cudaFree()进行释放。
另外,在从主机内存复制到GPU上的常量内存时,需要使用特殊版本的cudaMemcpy(),它就是cudaMemcpyToSymbol(),使用方法与cudaMemcpy()类似:
cudaMemcpyToSymbol(dev_s, spheres, SPHERES * sizeof(Sphere))cudaMemcpyToSymbol()与cudaMemcpy()的唯一区别是:cudaMemcpyToSymbol()会复制到常量内存,cudaMemcpy()会复制到全局内存。
至此就完成了修改,完整代码如下:
// ray_tracing_const
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <math.h>
#include "../../common/book.h"
#include "../../common/cpu_bitmap.h"
#define INF 2e10f
#define rnd( x ) (x * rand() / RAND_MAX)
#define DIM 1024
#define SPHERES 20
struct Sphere
{
float r, g, b; // 球面的颜色
float radius; // 球面半径
float x, y, z; // 球面的中心坐标(x,y,z)
// 对于来自(ox,oy)处的光线,计算是否会与这个球面相交,
// 如果相交,计算从相机到光线命中球面处的距离
__device__ float hit(float ox, float oy, float* n) {
float dx = ox - x;
float dy = oy - y;
if (dx * dx + dy * dy < radius * radius) {
float dz = sqrtf(radius * radius - dx * dx - dy * dy);
*n = dz / sqrtf(radius * radius);
return dz + z;
}
return -INF;
}
};
// 常量内存,需要静态分配
__constant__ Sphere dev_s[SPHERES];
__global__ void kernel(unsigned char* ptr) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
float ox = (x - DIM / 2);
float oy = (y - DIM / 2);
float r = 0, g = 0, b = 0;
float maxz = -INF;
for (int i = 0; i < SPHERES; i++) {
float n;
float t = dev_s[i].hit(ox, oy, &n);
if (t > maxz) {
float fscale = n;
r = dev_s[i].r * fscale;
g = dev_s[i].g * fscale;
b = dev_s[i].b * fscale;
maxz = t;
}
}
ptr[offset * 4 + 0] = (int)(r * 255);
ptr[offset * 4 + 1] = (int)(g * 255);
ptr[offset * 4 + 2] = (int)(b * 255);
ptr[offset * 4 + 3] = 255;
}
int main() {
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_ptr;
HANDLE_ERROR(cudaMalloc((void**)&dev_ptr, bitmap.image_size()));
Sphere* spheres = (Sphere*)malloc(SPHERES * sizeof(Sphere));
for (int i = 0; i < SPHERES; i++) {
spheres[i].r = rnd(1.0f);
spheres[i].g = rnd(1.0f);
spheres[i].b = rnd(1.0f);
spheres[i].x = rnd(1000.0f) - 500;
spheres[i].y = rnd(1000.0f) - 500;
spheres[i].z = rnd(1000.0f) - 500;
spheres[i].radius = rnd(100.0f) + 20;
}
// 使用特殊的内存拷贝函数cudaMemcpyToSymbol()将主机内存拷贝到GPU,使用方法与cudaMemcpy类似
HANDLE_ERROR(cudaMemcpyToSymbol(dev_s, spheres, SPHERES * sizeof(Sphere)));
free(spheres);
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel<<<blocks, threads>>>(dev_ptr);
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_ptr,
bitmap.image_size(),
cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
//HANDLE_ERROR(cudaFree(dev_s)); 不需要使用cudaFree()对常量内存dev_s进行释放
HANDLE_ERROR(cudaFree(dev_ptr));
return 0;
}最后,改为常量内存会给我们的程序带来怎样的性能提升,将在下一篇介绍。
参考:
- 《GPU高性能编程 CUDA实战》








评论 (0)