

本系列代码托管于:https://github.com/chintsan-code/cuda_by_example
本篇使用的项目为:dot、shared_bitmap
在前面(CUDA实战笔记(6)——使用线程实现GPU上的矢量求和)提到Block中的并行Thread能够实现并行Block无法完成的工作,但我们之前并没有用到相关的特性,只是为了解决Block数量的硬件限制。如果只是为了解决硬件限制,CUDA Runtime完全可以在后台自动完成,显然,还有其他的动机需要将Block分解成多个Thread。
CUDA C支持共享内存。使用共享内存类似于__device__和__global__这样的C语言扩展。它的关键字是__shared__,使用的时候将这个关键字添加到变量声明中,这将使得这个内存驻留在共享内存中。这相当与在标准C中声明一个static或volatile类型的变量。
CUDA C编译器(NVCC)对共享内存中的变量与普通变量将采取不同的处理方式。对于GPU上启动的每一个Block,NVCC都将创建该变量的一个副本。Block中的每个Thread都共享这块内存,但是却无法看到也不能修改其他Block中的变量副本。这就实现了一种机制:在同一个Block中,多个Thread能够在计算上进行通信和协作。而且,由于共享内存缓存区是驻留在GPU上的,因此在访问共享内存是的延迟要远远低于访问普通缓冲区的延迟,这使得共享内存想每个Block的高速缓存或者中间结果暂存器那样高效。
在CPU上进行多线程编程往往伴随着竞态条件(Race Condition),同样的,在GPU上也不例外。例如,如果线程A将一个值写入到共享内存,并且我们希望线程B对这个值进行一些操作,那么正确的做法是:只有当线程A的写入操作完成后,线程B才可以开始执行它的操作。因此我们需要一种同步的机制来处理这种问题。
一. 点积运算
如果对两个包含4个元素的矢量进行点击运算,那么公式是:
$$(x_0,x_1,x_2,x_3) \cdot (y_0,y_1,y_3,y_3)=x_0y_0+x_1y_1+x_2y_2+x_3y_3$$
可以看出,矢量的点积运算就是先将两个矢量中的对应元素相乘,然后将这些值加起来得到一个标量输出。
首先编写点积的核函数:
__global__ void dot(float* a, float* b, float* c) {
__shared__ float cache[threadsPerBlock];
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
}在这段代码中声明了一个共享内存缓存区,名为cache。因为一个Thread需要计算多个矢量元素的乘积,例如有4个Thread要计算元素个数为8的两个矢量点积:
- Thread0计算:\(x_0y_0\)、\(x_4y_4\)
- Thread1计算:\(x_1y_1\)、\(x_5y_5\)
- Thread2计算:\(x_2y_2\)、\(x_6y_6\)
- Thread3计算:\(x_3y_3\)、\(x_7y_7\)
而cache就是用于存储每一个Thread的加和值:
- cache[0] = \(x_0y_0+x_4y_4\)
- cache[1] = \(x_1y_1+x_5y_5\)
- cache[2] = \(x_2y_2+x_6y_6\)
- cache[3] = \(x_3y_3+x_7y_7\)
之后,需要将cache中所有的值相加起来。在执行这个累加运算之前,需要保证所有对cache的写入操作都已经完成了:
// 对Block中的Thread进行同步
__syncthreads();这个__syncthreads()函数将确保Block中的每个线程都执行完它之前的语句后,才会执行下一条语句。也就是说,当有一个Thread执行了__syncthreads()后的一条语句时,同一Block中的其他Thread肯定也执行完了__syncthreads()。
为了集合多线程高效求和,这里使用了归约(Reduction)算法,基本思想是:每个线程将cache[]中的两个值相加起来,然后将结果保存会cache[]。由于每个线程都将cache[]中的两个值合并为一个值,那么在完成这一步骤之后,得到的结果数量就是一开始数量的一半。接着重复这一过程,在执行\(log_2(threadsPerBlock)\)个步骤之后,就可以得到cache[]中所有值的总和。
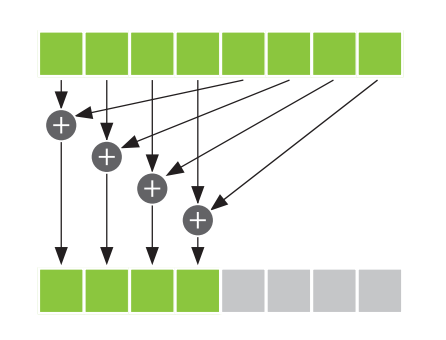
// 归约(Reduction)算法求和
// 对于归约运算来说,以下代码要求threadsPerBlock必须是2的倍数
int i = blockDim.x / 2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}在第一个步骤中,取threadsPerBlock的一半作为初始i值,只有索引小于这个值的线程才会执行。只有当Thread的索引小于i时,才可以把cache[]的两个数据项相加起来,因此将加法运算放在if条件中。执行加法运算的线程将cache[]中线程索引位置的值和线程索引加上i得到的位置上的值相加起来,并将结果保存会cache[]中线程索引位置上。
在完成一个求和步骤之后,如果要继续下一个步骤,必须保证所有写入cache[]的线程都已经执行完毕,因此需要再加一个线程同步操作__syncthreads()
注意,不能写成这样:
if (cacheIndex < i) {
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
}这种某些线程需要执行指定,另一些线程不需要执行的情况被称为线程发散(Thread Divergence)。在正常的环境中,发散的分支只会使得某些线程处于空闲,而其他线程将执行分支中的代码。但在__syncthreads()情况中则不同,CUDA架构会确保,除非Block中所有的Thread都执行了__syncthreads(),否则没有任何线程可以执行__syncthreads()之后的指令。也就是说,如果有Thread无法执行__syncthreads(),那么硬件将使所有的Thread保持等待,一直等,永久地等下去。
while循环结束之后,每一个Block都会得到一个累加的结果,存放在cache[0]中,它就是该Block中两两元素乘积的累加和。之后将他保存在全局内存c中,之后作为输出。c中就包含所有Block的累加结果。
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];这时还差最后一步,就是将c中的元素累加起来,在这里我们交给CPU来做。因为此时的数据量较小,如果用GPU来处理,通常会浪费计算资源。
最后剩下核函数的调用部分:
这里选择启动32个Block,并且每个Block包含256个线程。当N大于或等于8192(=32*256)时,不会有过多的线程造成浪费,此时1个Thread处理1个或多个矢量元素的乘积。
dot<<<32, 256>>>(dev_a, dev_b, dev_partial_c);但是,当N小于8192时,就可能出现线程的浪费,因此需要根据N的大小,修改启动的Block的数量。在这种情况下,假设要让每个Thread处理一对数据,那么启动的总的Thread的数量应该要大于或等于N,又因为启动的Block的数量应该是N/threadsPerBlock的整数倍且要向上取整,那么应该启动的Block的数量为:
const int threadsPerBlock = 256;
(N + threadsPerBlock - 1) / threadsPerBlock最后,我们取32个Block和上面计算的结果的较小值。即:当N小于或等于8182时,每个Thread处理一对矢量元素,单N大于8182时,存在Thread处理多对矢量元素。整理一下:
// 默认启动32个Block,每个Block包含256个Thread
// 当N小于8192时,这样启动就会造成Thread的浪费,需要减少启动的Block的数量
// 当N小于或等于8192时,每个Thread处理一对矢量元素;当N大于8192时,存在Thread处理多对矢量元素
const int N = 33 * 1024;
const int threadsPerBlock = 256;
const int blocksPerGrid = imin(32, (N + threadsPerBlock - 1) / threadsPerBlock);
dot<<<blocksPerGrid, threadsPerBlock>>>(dev_a, dev_b, dev_partial_c);在核函数执行完成之后,按前面所推,我们会得到一个数组,其中的元素是各个Block计算的元素乘积之和。接下来,需要将这个数组进行累加求和,这一步交给CPU处理:
c = 0;
for (int i = 0; i < blocksPerGrid; i++)
{
c += partial_c[i];
}最后验证结果。我们可以给这两个矢量a和b以特殊的值:
\(a_i = i\) 、\(b_i = 2i\)
因此有a和b的矢量点积结果:
$$a \cdot b = \sum_{i=0}^{N-1}{2i^2} = 2\sum_{i=0}^{N-1}{i^2}$$
可以根据下面的平方和数列求和公式对结果进行验证:
$$\sum_{i=0}^N{i^2}=\frac{N(N+1)(2N+1)}{6}$$
完整代码如下:
// dot
#ifdef __INTELLISENSE__
// in here put whatever is your favorite flavor of intellisense workarounds
void __syncthreads(void);
#endif
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
#define imin(a,b) (a<b?a:b)
#define sum_squares(x) (x*(x+1)*(2*x+1)/6)
// 默认启动32个Block,每个Block包含256个Thread
// 当N小于8192时,这样启动就会造成Thread的浪费,需要减少启动的Block的数量
// 当N小于或等于8192时,每个Thread处理一对矢量元素;当N大于8192时,存在Thread处理多对矢量元素
const int N = 33 * 1024;
const int threadsPerBlock = 256;
const int blocksPerGrid = imin(32, (N + threadsPerBlock - 1) / threadsPerBlock);
__global__ void dot(float* a, float* b, float* c) {
__shared__ float cache[threadsPerBlock]; // 使用关键字__shared__声明一个变量驻留在共享内存中
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N) {
// 一个Thread需要计算多个矢量元素的乘积
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// cache将对应threadIdx的Thread计算后的多个矢量元素的乘积累加起来
cache[cacheIndex] = temp;
// 对Block中的Thread进行同步
__syncthreads();
// 归约(Reduction)算法求和
// 对于归约运算来说,以下代码要求threadsPerBlock必须是2的倍数
int i = blockDim.x / 2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
int main() {
float *a, *b, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
float c;
a = (float*)malloc(N * sizeof(float));
b = (float*)malloc(N * sizeof(float));
partial_c = (float*)malloc(blocksPerGrid * sizeof(float));
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_partial_c, blocksPerGrid * sizeof(float)));
// 将两个矢量初始化为特殊的数列,方便之后使用平反和数列求和公式验证
for (int i = 0; i < N; i++) {
a[i] = i;
b[i] = i * 2;
}
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(float), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(float), cudaMemcpyHostToDevice));
dot<<<blocksPerGrid, threadsPerBlock>>>(dev_a, dev_b, dev_partial_c);
HANDLE_ERROR(cudaMemcpy(partial_c, dev_partial_c, blocksPerGrid * sizeof(float), cudaMemcpyDeviceToHost));
// 在CPU上完成最终的求和运算
c = 0;
for (int i = 0; i < blocksPerGrid; i++)
{
c += partial_c[i]; // partial_c[i]就是第i个Block返回的元素乘积之和,一共有blocksPerGrid个Block,把它们加起来得到最终结果
}
// 验证结果。应该与公式计算的结果一致
printf("Does GPU value %.6g = %.6g?\n", c, 2 * sum_squares((float)(N - 1)));
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaFree(dev_b));
HANDLE_ERROR(cudaFree(dev_partial_c));
free(a);
free(b);
free(partial_c);
return 0;
}二. 基于共享内存的位图
这里编写一个绘图程序:
int main() {
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_ptr;
HANDLE_ERROR(cudaMalloc((void**)&dev_ptr, bitmap.image_size()));
dim3 threads(16, 16);
dim3 blocks(DIM / 16, DIM / 16);
kernel<<<blocks, threads>>>(dev_ptr);
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_ptr, bitmap.image_size(), cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
HANDLE_ERROR(cudaFree(dev_ptr));
return 0;
}与前面的绘制Julia集一样,为每个像素分配一个Thread。区别在于之前是每个Block只有一个Thread,现在是每个Block有(16,16)个Thread。
接着编写核函数:
__global__ void kernel(unsigned char* ptr) {
// 将threadIdx/blockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
// 声明一个共享缓冲区,因为要让CUDA Runtime启动的block有(16,16)个线程,所有缓冲区大小也设置为16*16,
// 让每个线程在该缓冲区中都有一个对应的位置
__shared__ float shared[16][16];
// 现在计算这个位置上的的值
const float period = 128.0f;
shared[threadIdx.x][threadIdx.y] =
255 * (sinf(x * 2.0f * PI / period) + 1.0f) *
(sinf(y * 2.0f * PI / period) + 1.0f) / 4.0f;
__syncthreads();
// 最后,把这些值保存回像素,保留x和y的次序
ptr[offset * 4 + 0] = 0;
// 注意这里,当索引为(threadIdx.x, threadIdx.y)的Thread完成对缓冲区shared的写入后,要在这里对
// shared[15 - threadIdx.x][15 - threadIdx.y]进行读取时,
// 索引为(15 - threadIdx.x, 15 - threadIdx.y)的Thread可能还没完成对缓冲区shared的写入,
// 因此需要在之前加上__syncthreads();
ptr[offset * 4 + 1] = shared[15 - threadIdx.x][15 - threadIdx.y];
ptr[offset * 4 + 2] = 0;
ptr[offset * 4 + 3] = 255;
}在这里声明了一个16*16的共享缓冲区,之所以要这么大的尺寸,是因为在核函数调用部分,我们告诉CUDA Runtime让每一个Block都有(16, 16)个Thread。
重点在于图像的绘制渲染部分,设想一下:当索引为(threadIdx.x, threadIdx.y)的线程需要将计算值保存为图像像素时,它需要对shared[15 - threadIdx.x][15 - threadIdx.y]中的值进行读取,但是shared[][]中这个位置是由索引为(15 - threadIdx.x, 15 - threadIdx.y)的线程负责写入的。假如在这之前没有加上同步代码部分__syncthreads(),那么就可能会出现ptr[offset * 4 + 1]为0的情况(如果还没对这个位置进行写入)。
最后附上完整程序:
// shared_bitmap
#ifdef __INTELLISENSE__
// in here put whatever is your favorite flavor of intellisense workarounds
void __syncthreads(void);
#endif
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "math.h"
#include "../../common/book.h"
#include "../../common/cpu_bitmap.h"
#define DIM 1024
#define PI 3.1415926535897932f
__global__ void kernel(unsigned char* ptr) {
// 将threadIdx/blockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * gridDim.x * blockDim.x + x;
// 声明一个共享缓冲区,因为要让CUDA Runtime启动的block有(16,16)个线程,所有缓冲区大小也设置为16*16,
// 让每个线程在该缓冲区中都有一个对应的位置
__shared__ float shared[16][16];
// 现在计算这个位置上的的值
const float period = 128.0f;
shared[threadIdx.x][threadIdx.y] =
255 * (sinf(x * 2.0f * PI / period) + 1.0f) *
(sinf(y * 2.0f * PI / period) + 1.0f) / 4.0f;
__syncthreads();
// 最后,把这些值保存回像素,保留x和y的次序
ptr[offset * 4 + 0] = 0;
// 注意这里,当索引为(threadIdx.x, threadIdx.y)的Thread完成对缓冲区shared的写入后,要在这里对
// shared[15 - threadIdx.x][15 - threadIdx.y]进行读取时,
// 索引为(15 - threadIdx.x, 15 - threadIdx.y)的Thread可能还没完成对缓冲区shared的写入,
// 因此需要在之前加上__syncthreads();
ptr[offset * 4 + 1] = shared[15 - threadIdx.x][15 - threadIdx.y];
ptr[offset * 4 + 2] = 0;
ptr[offset * 4 + 3] = 255;
}
int main() {
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_ptr;
HANDLE_ERROR(cudaMalloc((void**)&dev_ptr, bitmap.image_size()));
dim3 threads(16, 16);
dim3 blocks(DIM / 16, DIM / 16);
kernel<<<blocks, threads>>>(dev_ptr);
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_ptr, bitmap.image_size(), cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
HANDLE_ERROR(cudaFree(dev_ptr));
return 0;
}执行效果:

参考:
- 《GPU高性能编程 CUDA实战》








评论 (0)