

本系列代码托管于:https://github.com/chintsan-code/cuda_by_example
本篇使用的项目为:add_loop_blocks、add_loop_long_blocks、add_loop_very_long_blocks
在之前的篇章(CUDA实战笔记(4)——矢量求和运算)中,在基于GPU实现矢量求和部分,我们通过add<<N, 1>>告诉CUDA Runtime启动N个核函数副本,我们将这些副本称为线程块(Block)。这就是尖括号中第一个参数的作用。第二个参数表示CUDA Runtime在每个Block中创建的线程(Thread)数量,在那个例子例子中,每个Block中只包含一个Thread。因此add<N, 1>总共让CUDA Runtime启动了N*1 = N个并行线程。
一. 使用线程实现GPU上的矢量求和
下面将使用Thread代替Block实现矢量求和。在这一问题上这种改变几乎没有任何优势,但是Block中的并行Thread能够实现并行Block无法完成的工作。
首先修改核函数add的调用部分,之前是启动N个Block,每个Block包含1个Thread。现在要改为启动1个Block,它包含N个Thread:
add<<<1, N>>>(dev_a, dev_b, dev_c);接着要修改核函数add,之前是通过Block的索引blockIdx实现数输入输出的数据进行索引的,现在只启动1个Block,自然是要对着部分进行修改:
__global__ void add(int* a, int* b, int* c)
{
int tid = threadIdx.x; // 只有一个Block,可以通过线程索引来对数据进行索引
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}这样就完成了修改,完整代码如下:
// add_loop_blocks
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
#define N 10
__global__ void add(int* a, int* b, int* c) {
int tid = threadIdx.x; // 只有一个Block,通过线程索引来对数据进行索引
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
int main() {
int a[N], b[N], c[N];
int* dev_a, * dev_b, * dev_c;
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));
for (int i = 0; i < N; i++)
{
a[i] = -i;
b[i] = i * i;
}
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice));
add<<<1, N>>>(dev_a, dev_b, dev_c); // 启动1个Block,它包含N个Thread
HANDLE_ERROR(cudaMemcpy(c, dev_c, sizeof(int) * N, cudaMemcpyDeviceToHost));
for (int i = 0; i < N; i++)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaFree(dev_b));
HANDLE_ERROR(cudaFree(dev_c));
return 0;
}下面会对这种只使用Thread的方法中存在的局限进行说明:
二. 在GPU上对更长的矢量求和
在《CUDA实战笔记(4)——矢量求和运算》的末尾,有提到由于硬件限制,Block的数量是有限的,同样的,每一个Block中的Thread数量也是有限的。可以通过cudaDeviceProp.maxThreadsPerBlock获取每一个Block中的最大Thread数量,我这里是1024。
现在使用多个Block,每个Block包含多个Thread,计算索引看上去非常类似于将二维索引空间转换为一维空间:
int tid = blockIdx.x * blockDim.x + threadIdx.x;这里出现了一个全新的内置变量blockDim。对于所有Block来说,这个变量是一个常数,它等于Block中每一维的Thread的数量。由于本次修改只用到一维的Block,因此只用到blockDim.x,类似之前使用过的gridDim。本次问题的线程块和线程的的空间组织形式如下:
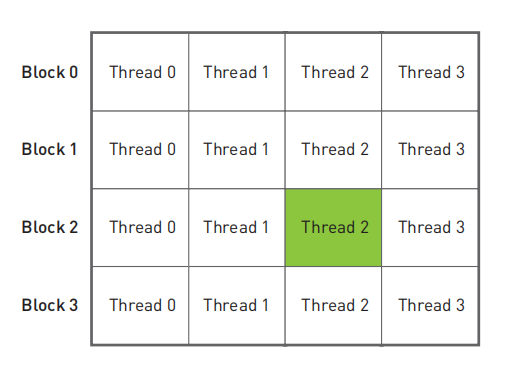
如果用Block表示行,用Thread表示列,那么就可以计算得到唯一的索引。例如要计算上图中绿色背景的Thread在在线性空间中的唯一索引,那么就是:
int tid = blockIdx.x * blockDim.x + threadIdx.x; // 2 * 4 + 2 = 10既然修改为多个Block和多个Thread的模型,那么调用核函数的部分也需要一起进行修改,仍然是启动N个并行线程,但是为了不超过Block中Thread的最大限制1024,将每一个Block中的Thread数量设置为128,然后启动N/128个Block,这样就启动了N个Thread同时并行运行。
但是这样会引入一个新的问题,如果N不是128的倍数,例如N为127,那么就会启动0个Block,这就无法计算,实际上,如果N不是128的倍数,启动的Block都会少于预期数量,因此我们希望N/128的结果可以向上取整:
add<<<(127 + N) / 128, 128>>>(dev_a, dev_b, dev_c); // (127 + N) / 128 : N/128向上取整上面的代码保证了当N不为128的整数倍时,启动比预期更多的Block,既然有可能启动多余的Block和Thread,那么久需要有一种机制,可以保证这些多余的Block和Thread不参与运算,其实之前我们一直在使用这种机制:
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}当索引tid越过数组时,核函数会自动停止执行计算,更重要的是,核函数不会越过数组边界对内存进行读写。
完整代码如下:
// add_loop_long_blocks
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
#define N (33*1024) // 这么大的N,如果只用一个Block是做不了的
__global__ void add(int* a, int* b, int* c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
// 当N很大时要修改项目属性->配置属性->链接器->系统->堆栈保留大小(单位: byte)
// 或者分配在全局区或堆区
// int a[N], b[N], c[N]; // 分配在全局区
int main() {
//int a[N], b[N], c[N]; // 分配在栈区
int* a, * b, * c;
a = (int*)malloc(N * sizeof(int)); // 分配在堆区,最后记得要释放
b = (int*)malloc(N * sizeof(int));
c = (int*)malloc(N * sizeof(int));
int* dev_a, * dev_b, * dev_c;
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));
for (int i = 0; i < N; i++)
{
a[i] = -i;
b[i] = i * i;
}
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice));
// (127 + N) / 128 : N/128向上取整
// 每个Block有128个Thread
// 注意( N + 127 ) / 128不能超过maxGridSize的限制
add<<<(127 + N) / 128, 128>>>(dev_a, dev_b, dev_c);
HANDLE_ERROR(cudaMemcpy(c, dev_c, sizeof(int) * N, cudaMemcpyDeviceToHost));
for (int i = 0; i < N; i++)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaFree(dev_b));
HANDLE_ERROR(cudaFree(dev_c));
free(a); // 释放之前分配的堆区内存
free(b);
free(c);
return 0;
}这样修改之后基本可以满足相当大的N长度的矢量相加了,但是受限于硬件,Grid中包含的Block也是有限的,可以通过cudaDeviceProp.maxGridSize获取Grid每一维度的Block上限,我这里是(2147483647, 65535, 65535),因此如果上面的N超过了(2^31 – 1)*128,那么核函数就会调用失败(当然在调用核函数之前,由于显存不足就会报错:out of memory了)。
假设我们的Grid最大可以包含65535个Block(以前的GPU是这样的),且不会出现显存不足的问题。那么当如果上面的N超过了 65535 *128,那么核函数就会调用失败。下面来解决这个问题。
三. 在GPU上对任意长度的矢量求和
首先对核函数进行一些修改:
__global__ void add(int* a, int* b, int* c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
while (tid < N) {
c[tid] = a[tid] + b[tid];
tid += gridDim.x * blockDim.x;
}
}这类似于最初CPU版本的实现:
void add(int* a, int* b, int* c)
{
int tid = 0; // 这是第0个CPU,因此索引从0开始
while (tid < N)
{
c[tid] = a[tid] + b[tid];
tid += 1; // 由于我们只有一个CPU,因此每次递增1
}
}在这里,使用了一个while循环对数据进行迭代,在CPU版本中,每次递增的数量是CPU的数量,在GPU中的实现也是同样的道理:由于硬件的限制,有时候没办法让每个数据都被一个Thread独立处理,因此可以让一个Thread处理多个数据。
我们希望每个并行Thread从不同的索引开始,因此每个线程的索引按照以下公式获取:
int tid = blockIdx.x * blockDim.x + threadIdx.x;当该线程处理完一个数据之后,加上一个步长,处理下一个数据,直到数据的索引超过矢量长度N。关键点就在这个步长应该怎么得到。可以这么理解:当启动了10个Thread,要处理100个数据,而1个Thread只能同时处理一个数据。那么有:
- Thread0处理:第0、10、20、30、40、50、60、70、80、90个数据
- Thread1处理:第1、11、21、31、41、51、61、71、81、91个数据
- …
- Thread9处理:第9、19、29、39、49、59、69、79、89、99个数据
可以看到,步长其实就等于启动的Thread数量,而
$$启动的Thread数量 = 启动的Block数量 * 每个Block包含的线程数量$$
于是有
tid += gridDim.x * blockDim.x;其中gridDim.x就是在这个矢量求和问题中启动的Block数量,blockDim.x就是每个Block中包含Thread的数量。
核函数就修改完成了,接下来修改它的调用部分。前面说过,如果启动的Block大于硬件设置,就会调用失败,因此要减少Block的数量,这里将Block的数量固定为某一个较小的值。例如128:
add<<<128, 128 >>>(dev_a, dev_b, dev_c);这样我们就启动了128个Block,每个Block包含128个Thread。
在之前,总共启动N个Thread,每个Thread只需要处理1个数据。现在是启动128*128个Thread,每个Thread分别要处理N/16384个数据。
当前,也可以调节Block和Thread到合适的大小。
下面是完整代码。
// add_loop_very_long_blocks
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
#define N (65536*1024)
__global__ void add(int* a, int* b, int* c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
while (tid < N) {
c[tid] = a[tid] + b[tid];
tid += gridDim.x * blockDim.x; // 步长:启动的Thread的数量 = 启动的Block数量(gridDim.x) * 每个Block包含的Thread的数量(blockDim.x)
// 让每个Thread处理 N / (gridDim.x * blockDim.x)个数据
}
}
int main() {
int* a, * b, * c;
a = (int*)malloc(N * sizeof(int));
b = (int*)malloc(N * sizeof(int));
c = (int*)malloc(N * sizeof(int));
int* dev_a, * dev_b, * dev_c;
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));
for (int i = 0; i < N; i++)
{
a[i] = -i;
b[i] = i * i;
}
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice));
// 启动128个Block,每个Block含有128个线程
// 让每个Thread处理 N / 16384个数据
add<<<128, 128>>>(dev_a, dev_b, dev_c);
HANDLE_ERROR(cudaMemcpy(c, dev_c, sizeof(int) * N, cudaMemcpyDeviceToHost));
for (int i = 0; i < N; i++)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaFree(dev_b));
HANDLE_ERROR(cudaFree(dev_c));
free(a);
free(b);
free(c);
return 0;
}参考:
- 《GPU高性能编程 CUDA实战》








评论 (0)