

本系列代码托管于:https://github.com/chintsan-code/cuda_by_example
本篇使用的项目为:ripple
在上一篇中,使用线程实现了矢量求和,其中用到的Block和Thread都是一维的,本篇使用二维的Block和Thread实现动画效果。当然我们只关注GPU在这一问题中是怎么处理并行计算的,并不关心动画效果是怎么呈现和显示的。
完整代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
#include "../../common/cpu_anim.h"
#define DIM 1024
#define PI 3.1415926535897932f
__global__ void kernel(unsigned char* ptr, int ticks) {
// 将threadIdx/blockIdx映射到像素位置
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * blockDim.x * gridDim.x + x;
// 下面的代码与动画有关,不用管了
float fx = x - DIM / 2;
float fy = y - DIM / 2;
float d = sqrtf(fx * fx + fy * fy);
unsigned char grey = (unsigned char)(128.0f + 127.0f *
cos(d / 10.0f - ticks / 7.0f) /
(d / 10.0f + 1.0f));
ptr[offset * 4 + 0] = grey;
ptr[offset * 4 + 1] = grey;
ptr[offset * 4 + 2] = grey;
ptr[offset * 4 + 3] = 255;
}
struct DataBlock
{
unsigned char* dev_bitmap;
CPUAnimBitmap* bitmap;
};
void generate_frame(DataBlock* d, int ticks) {
// (DIM/16, DIM/16)个Block组成一个Grid
// 每个Block中有(16, 16)个Thread
// 所以一共有(DIM, DIM)个Thread,对应DIM*DIM尺寸的图像,每一个像素由一个Thread处理
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel<<<blocks, threads>>>(d->dev_bitmap, ticks);
HANDLE_ERROR(cudaMemcpy(d->bitmap->get_ptr(),
d->dev_bitmap,
d->bitmap->image_size(),
cudaMemcpyDeviceToHost));
}
// 释放在GPU上分配的显存
void cleanup(DataBlock* d) {
HANDLE_ERROR(cudaFree(d->dev_bitmap));
}
int main() {
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
HANDLE_ERROR(cudaMalloc((void**)&data.dev_bitmap, bitmap.image_size()));
// 每次生成一帧图像,调用一次generate_frame,之后将分配的显存释放掉
bitmap.anim_and_exit((void(*)(void*, int))generate_frame,
(void(*)(void*))cleanup);
return 0;
}关于动画的大部分复杂代码都被封装在CPUAnimBitmap中,这里我们并不关心。
既然是动画效果,那就会有动画帧的概念。在这里通过generate_frame()函数生成动画帧,当要生成一帧新的动画时,就会调用一次generate_frame()
void generate_frame(DataBlock* d, int ticks) {
// (DIM/16, DIM/16)个Block组成一个Grid
// 每个Block中有(16, 16)个Thread
// 所以一共有(DIM, DIM)个Thread,对应DIM*DIM尺寸的图像,每一个像素由一个Thread处理
dim3 blocks(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel<<<blocks, threads>>>(d->dev_bitmap, ticks);
HANDLE_ERROR(cudaMemcpy(d->bitmap->get_ptr(),
d->dev_bitmap,
d->bitmap->image_size(),
cudaMemcpyDeviceToHost));
}首先声明了两个二维变量blocks和threads。blocks表示在Grid中包含Block的数量,threads表示每一个Block中包含的Thread的数量,由于生成的是一副图像,因此使用了二维索引,并且每一个线程都有一个唯一的索引(x, y),这样就可以很容易地与输出图像中的像素一一对应起来。因为我们设置了Block中含有(16, 16)个Thread,为了让每一一个Thread都能对应DIM*DIM大小的图像中的每一个像素,所以Grid中应该包含(DIM/16, DIM/16)个Block。
假如这幅图像大小是48*32,那么线程模型应该如下图所示:
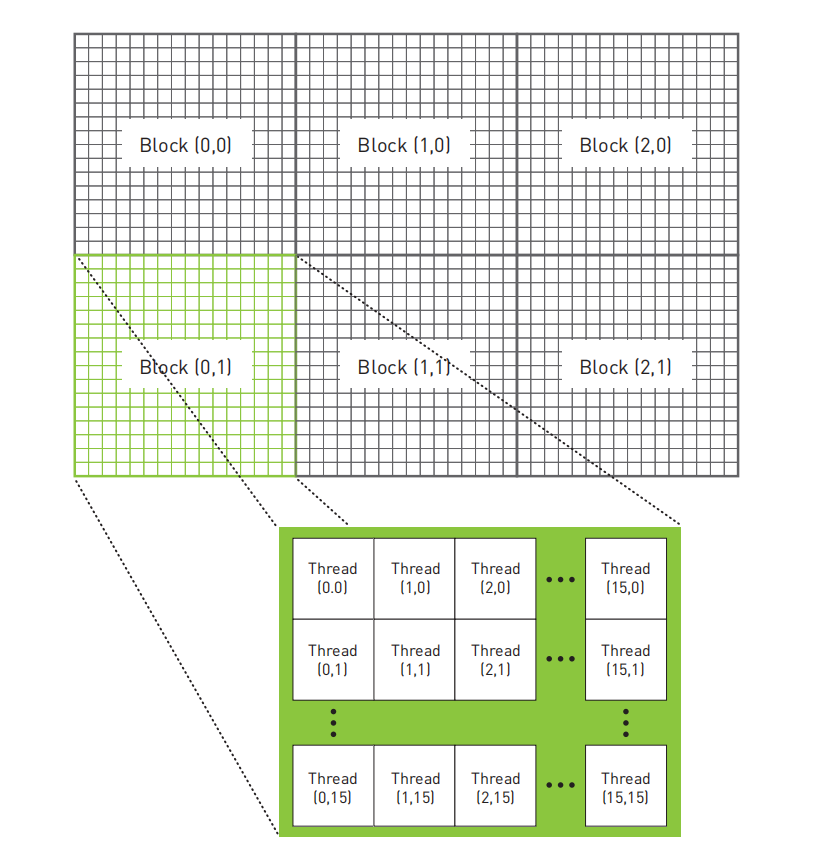
对照上图的线程模型,就可以理解在核函数kernel()中,是如何将Thread与每一个像素一一映射的了:
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int offset = y * blockDim.x * gridDim.x + x;例如,当位于Grid中(12, 8)处的Block中的(3, 5)处的Thread开始执行时,它可以知道在其左边有12个Block,在其上方有8个Block。在这个Block中,(3, 5)处的Thread左边有3个Thread,上方有5个Thread。由于每个Block都有(16,16)个线程,这意味着这个线程在整个Grid中有:
12个Block * 16个Thread / Block + 3个Thread = 195个Thread在其左边
8个Block * 16个Thread / Block + 5个Thread = 133个Thread在其上方又因为在这个Grid中,有(DIM/ 16, DIM/16)个Block,每个Block中有(16, 16)个Thread,因此将x和y进行线性化从而得到输出缓冲区的一个偏移:
offset = 133 * 16 * DIM / 16 + 195 = 133 * DIM + 195最后动画的效果如下:

参考:
- 《GPU高性能编程 CUDA实战》








评论 (0)