

本系列代码托管于:https://github.com/chintsan-code/cuda_by_example
本篇使用的项目为:add_loop_cpu、add_loop_gpu
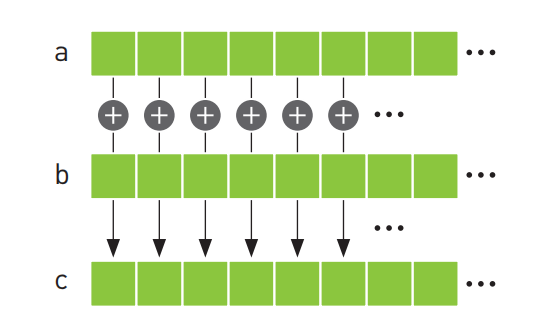
假设我们要实现这样的功能:将两组数组中对应位置的元素相加,并将计算结构保存在第三个数组中。这其实是个矢量求和运算的问题:
1. 基于CPU的矢量求和
首先看一下传统方式怎么解:
//add_loop_cpu
#include <stdio.h>
#define N 10
void add(int* a, int* b, int* c)
{
int tid = 0; // 这是第0个CPU,因此索引从0开始
while (tid < N)
{
c[tid] = a[tid] + b[tid];
tid += 1; // 由于我们只有一个CPU,因此每次递增1
}
}
int main()
{
int a[N], b[N], c[N];
// 初始化两个数组
for (int i = 0; i < N; i++)
{
a[i] = -i;
b[i] = i * i;
}
add(a, b, c);
// 打印结果
for (int i = 0; i < N; i++)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
return 0;
}需要注意的就是while循环中,这么写是为了可以在多个CPU或CPU核上并行运行。
因为这里只是为例举个例子,并没有真的实现并行运行,所以tid每次是递增1。如果加上多线程的代码,例如我们使用2个线程执行上面的代码,那么应该是在2个CPU上执行以下代码,每个线程都可以并行地执行add函数:
// 第1个CPU(核)
void add(int* a, int* b, int* c)
{
int tid = 0;
while (tid < N)
{
c[tid] = a[tid] + b[tid];
tid += 2;
}
}
// 第2个CPU(核)
void add(int* a, int* b, int* c)
{
int tid = 1;
while (tid < N)
{
c[tid] = a[tid] + b[tid];
tid += 2;
}
}2. 基于GPU的矢量求和
// add_loop_gpu
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
#define N 10
__global__ void add(int* a, int* b, int* c) {
int tid = blockIdx.x; // 当前执行着设备代码的线程块(Block)的索引,第一个线程块的索引为0
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
int main() {
int a[N], b[N], c[N];
int* dev_a, * dev_b, * dev_c;
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));
for (int i = 0; i < N; i++)
{
a[i] = -i;
b[i] = i * i;
}
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice));
// <<<b, t>>> b:设备在执行核函数时使用的并行线程块(Block)数量。t:CUDA Runtime在每个线程块中创建的线程数量
// N个线程块 * 1个线程/线程块 = N个并行线程
// 当启动核函数时,我们将并行线程块(Block)的数量指定为N。这个并行线程块集合也称为一个线程格(Grid),
// 这是告诉CUDA Runtime,我们想要一个一维的线程格,其中包含N个线程块。
add<<<N, 1 >>>(dev_a, dev_b, dev_c);
HANDLE_ERROR(cudaMemcpy(c, dev_c, sizeof(int) * N, cudaMemcpyDeviceToHost));
for (int i = 0; i < N; i++)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}add函数和前面最大的改变就是将while改为了if,因为我们现在希望的是一个线程执行一次add函数,因此不再需要while了。
add<<<N, 1>>>表示CUDA Runtime会创建N个核函数add副本,并以并行的方式运行它们。将每个并行执行环境都成为一个线程块(Block)。
__global__ void add(int* a, int* b, int* c) {
int tid = blockIdx.x; // 当前执行着设备代码的线程块(Block)的索引,第一个线程块的索引为0
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}在核函数中,blockIdx是内置的一个变量,表示当前执行设备代码的线程块的索引。之所以用blockIdx.x,是因为CUDA支持二维的线程块数组(这一特性对二维空间的计算问题会带来很大的便利,例如矩阵运算和图像处理)。
当启动核函数时,我们将并行线程块(Block)的数量指定为N。这个并行线程块集合也称为一个线程格(Grid)。因此add<<<N, 1>>>就是在告诉CUDA Runtime,我们需要一个一维的Grid,其中包含N个Block。
每个Block的索引(这里指的是blockIdx.x)的值都是不同的,在这个例子中,设置了10个Block,因此第一个Block索引blockIdx.x为0,最后一个为9。并且每一个Block并行执行,运行相同的代码,所以实际上它们执行起来是这样的:
// 第1个Block
__global__ void add(int* a, int* b, int* c) {
int tid = 0;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
// 第2个Block
__global__ void add(int* a, int* b, int* c) {
int tid = 1;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
// ......
// 第10个Block
__global__ void add(int* a, int* b, int* c) {
int tid = 9;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}这样就实现了矢量求和运算,而且是并行的。
关于为什么要在核函数中判断tid < N?
通常情况下,tid总是小于N的,因为在核函数中都是这么假设的。然而,我们仍会怀疑是否会有人去破坏这一假设。一旦出现这种破坏,会出现内存非法访问,这是很难排查的,事实上,这可能会终止核函数的运行,因为GPU有完善的内存管理机制,它将强制结束所有违反内存访问规则的进程。
其实就是为了防止数组访问越界。
最后需要注意的是,由于硬件限制,Block的数量并不是无限多的,因此N不能设太大,这个值可以通过cudaDeviceProp.maxGridSize属性获取每一维可容纳的Block数量,这将会在后面继续深入讲解。
参考:
- 《GPU高性能编程 CUDA实战》








评论 (0)