

本系列代码托管于:https://github.com/chintsan-code/cuda_by_example
本篇使用的项目为:enum_gpu、set_gpu
// enum_gpu
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
int main() {
cudaDeviceProp prop;
int count;
// 获取CUDA设备的数量
HANDLE_ERROR(cudaGetDeviceCount(&count));
for (int i = 0; i < count; i++) {
HANDLE_ERROR(cudaGetDeviceProperties(&prop, i));
// 设备序号
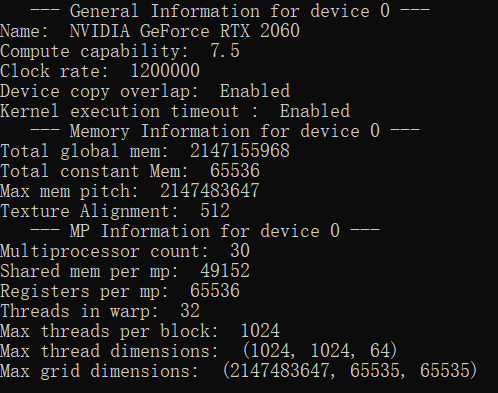
printf(" --- General Information for device %d ---\n", i);
// 标识设备的ASCII字符串
printf("Name: %s\n", prop.name);
// 设备的算力
printf("Compute capability: %d.%d\n", prop.major, prop.minor);
// 时钟频率(单位: kHz)
printf("Clock rate: %d\n", prop.clockRate);
// 设备是否可以同时复制内存并执行内核
printf("Device copy overlap: ");
if (prop.deviceOverlap)
printf("Enabled\n");
else
printf("Disabled\n");
// 指定内核是否有运行时间限制
printf("Kernel execution timeout : ");
if (prop.kernelExecTimeoutEnabled)
printf("Enabled\n");
else
printf("Disabled\n");
printf(" --- Memory Information for device %d ---\n", i);
// 设备上可用的全局内存(单位: byte)
printf("Total global mem: %ld\n", prop.totalGlobalMem);
// 设备上可用的恒定内存(单位: byte)
printf("Total constant Mem: %ld\n", prop.totalConstMem);
// 在内存复制的允许的最大间距(单位: byte)
printf("Max mem pitch: %ld\n", prop.memPitch);
// 纹理的对齐要求
printf("Texture Alignment: %ld\n", prop.textureAlignment);
printf(" --- MP Information for device %d ---\n", i);
// 设备上的多处理器数量
printf("Multiprocessor count: %d\n", prop.multiProcessorCount);
// 每个线程块(Block)可用的共享内存(单位: byte)
printf("Shared mem per mp: %ld\n", prop.sharedMemPerBlock);
// 每个线程块(Block)可用32位寄存器
printf("Registers per mp: %d\n", prop.regsPerBlock);
// 在一个线程束(Warp)中包含的线程数量
printf("Threads in warp: %d\n", prop.warpSize);
// 每一个线程块(Block)可包含的最大线程数量
printf("Max threads per block: %d\n", prop.maxThreadsPerBlock);
// 在多维线程块(Block)数组中,每一维可以包含的线程块数量
printf("Max thread dimensions: (%d, %d, %d)\n",
prop.maxThreadsDim[0],
prop.maxThreadsDim[1],
prop.maxThreadsDim[2]);
// 在每一个线程格(Grid)中,每一维可以包含的线程块(Block)数量
printf("Max grid dimensions: (%d, %d, %d)\n",
prop.maxGridSize[0],
prop.maxGridSize[1],
prop.maxGridSize[2]);
printf("\n");
}
return 0;
}
需要注意的是compute capability虽然经常被翻译为”算力”,但其实真实含义和字面意义上描述性能的”计算能力”并没有关系。也有将其翻译成”计算功能集”的,这与不同架构的CPU有着不同的功能和指令集(例如MMX、SSE、SSE2等)类似。cc 越高,说明GPU的工具包越新,支持的功能越新。可以理解为高版本的cc是低版本cc的超集,向下兼容。
在NVIDIA上的CUDA FAQ上,有这个问题,原文如下:
Q: What is the “compute capability”?
A: The compute capability of a GPU determines its general specifications and available features. For a details, see the Compute Capabilities section in the CUDA C Programming Guide.
如果在系统中有多个GPU,我们希望选择其中最适合的来处理我们的任务,例如选择拥有最多处理器的GPU来执行代码,使得速度最快;或者当核函数需要与CPU之间进行密集交互时,选择集成的GPU,因为它可以和CPU共享内存。这两个属性都可以通过上面的cudaGetDeviceProperties()来查询。
设备属性的基本使用方法如下:
// set_gpu
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include "../../common/book.h"
int main()
{
cudaDeviceProp prop;
int dev;
HANDLE_ERROR(cudaGetDevice(&dev));
printf("ID of current CUDA device: %d\n", dev);
memset(&prop, 0, sizeof(cudaDeviceProp));
prop.major = 1; // 设置选择条件,算力>1.3
prop.minor = 3;
HANDLE_ERROR(cudaChooseDevice(&dev, &prop)); //返回最匹配的设备id(若所有设备都没达到条件,也会返回一个最匹配的)
printf("ID of CUDA device closest to revision 1.3: %d\n", dev);
HANDLE_ERROR(cudaSetDevice(dev)); // 设置GPU设备,之后所有的设备操作都将在此设备上执行
return 0;
}在填充完cudaDeviceProp结构之后,将其传递给cudaChooseDevice(),这样CUDA Runtime将查找是否存在有某个设备符合这些条件,这将返回该GPU的ID,随后我们就可以通过cudaSetDevice()来进行设置,之后所有的设备操作都将在此GPU上执行。
参考:
- 《GPU高性能编程 CUDA实战》
- CUDA FAQ








评论 (0)