


0x00 The Deal
1. Bounding Box Prediction
- YOLOv3预测每个bbox的objectness score改为用逻辑回归(sigmoid)
- 有9个anchor(3个尺度各3各),与gt box的IOU最大的那个anchor box负责拟合该gt box,且置信度为1
- YOLOv1和v2中,置信度都为预测框与gt box 的IOU,而v3改为了二分类。预测框会分为3类:
- IOU最大的那个直接为1,即为正样本。正样本会对分类和定位都做出贡献
- 会有有一个阈值,比如0.5,大于阈值但不是最大IOU的那个都会被忽略
- 小于上面那个阈值的那些预测框的置信度设为0,为负样本。负样本只对置信度学习做出贡献
- 即:最好的作为正样本,小于0.5的作为负样本,其他忽略)
- 每个gt box只会分配一个anchor box(预测框)来进行预测
- 用IOU作为置信度标签有何不好?
- 假如很多预测框与gt box的IOU最高只有0.7(最好的学生只有70分,取其中得其下),这样模型就学不到好的效果,如果直接把置信度设为1,就是告诉模型这就是正样本,要好好学习
- COCO中的小目标,IOU对像素偏移很敏感,无法有效学习
- YOLOv1和v2中,置信度都为预测框与gt box 的IOU,而v3改为了二分类。预测框会分为3类:
2. Class Prediction
- YOLOv3对每个预测框使用多类别分类标签
- 不使用softmax预测分类标签(所有概率加起来为1,各个类别是互斥的)
- 而是每个预测框的每个类别逐一用逻辑回归输出概率(每个类别输出的概率都为0到1之间,可以有多个类别是高概率,不是互斥的)
- 在训练过程中,对于类别预测,我们使用二分类交叉熵损失函数
- 这样就可以用于谷歌Open Image Dataset这样多标签的数据集(例如一个对象的标签既是女人又是人)
3. Predictions Across Scales
多尺度目标检测(网络拓扑结构)
- YOLOv3在3种不同的尺度上进行预测
- 受到FPN(特征金字塔网络)的启发
- 获得3个feature map,每个feature map都有255个通道
- 255个通道:每个grid cell 有3个anchor,每个anchor有85个数(85:4+1+80)
- 4:x、y、w、h
- 1:objectness score
- 80:类别的条件概率
- 255个通道:每个grid cell 有3个anchor,每个anchor有85个数(85:4+1+80)

- 13×13的经过2倍上采样后和26×26的沿着通道方向进行拼接;同理26×26的经过2倍上采样和52×52拼接
- 这样既融合了深层抽象特化语义信息,又结合了浅层细粒度像素结构信息
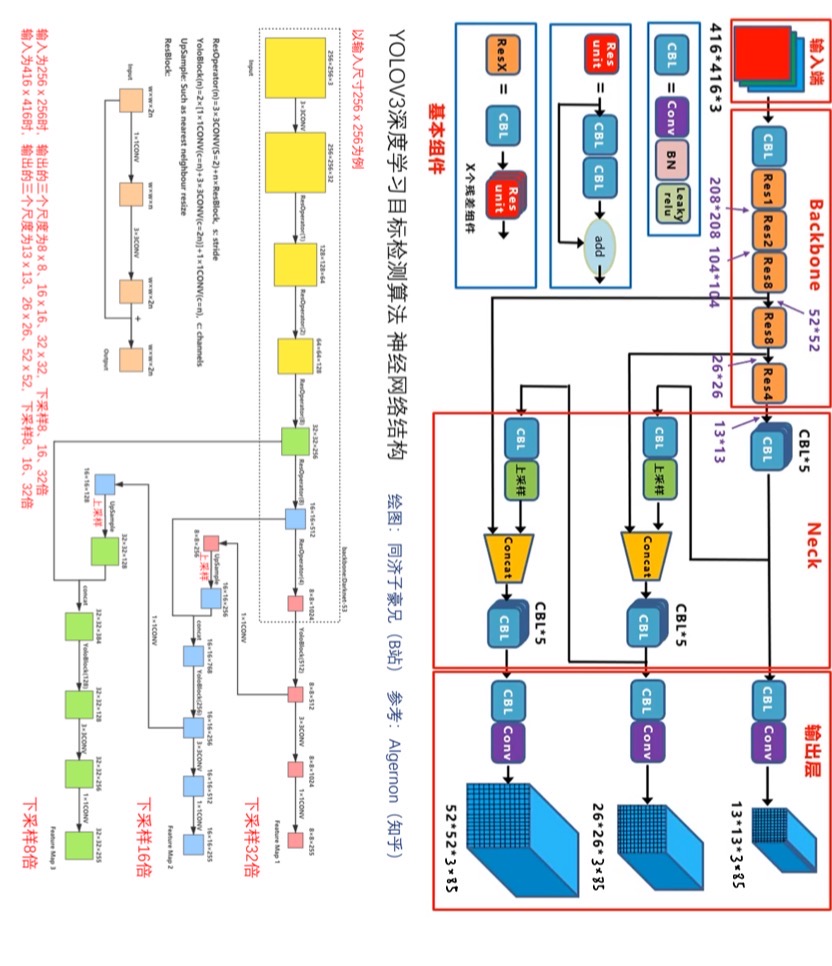
- 依然是对数据集做k-means聚类来产生anchor,总共产生9个anchor,每个尺度各分配3个anchor
4. Feature Extractor
特征提取backbone骨干网络:Darknet-53
- 混合了Darknet19和ResNet
- 采用了连续的3×3和1×1卷积层和shortcut短路连接
- 总共有52个卷积层+1个全连接层
- 用步长为2的卷积层做下采样,不使用池化了
- 在训练结束后会去掉全局平均池化层和全连接层,变成一个全卷积网络

0x01 How We Do
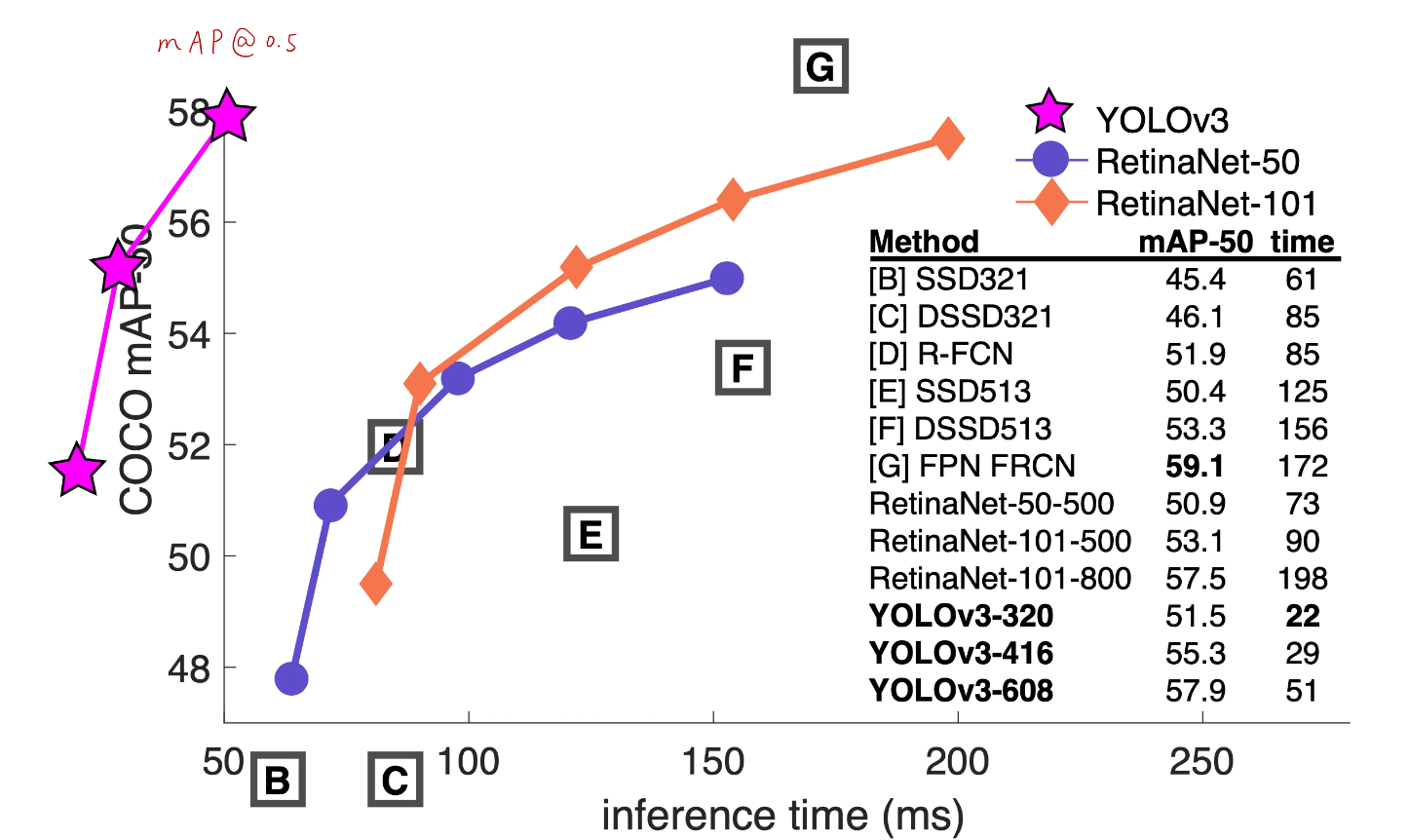
- 在IOU阈值为0.5的指标下,YOLOv3的表现很不错
- 但是如果IOU阈值调大,YOLOv3的表现就变差了,它的精确定位性能仍然较差
- 对小目标/密集目标的改进:
- grid cell个数增加(可以兼容任意尺寸的图片大小输入,但需要是32的整数倍)
- anchor机制
- 多尺度预测(FPN)
- 损失函数惩罚小框项
- 网络结构(backbone跨层连接)
0x02 What This All Means
- diss了mAP.5-.95的不科学的地方:
- 人很难区分IOU的微小差异,一昧地追求高AP指标不合理
- 人类视觉对类别敏感,对定位不敏感
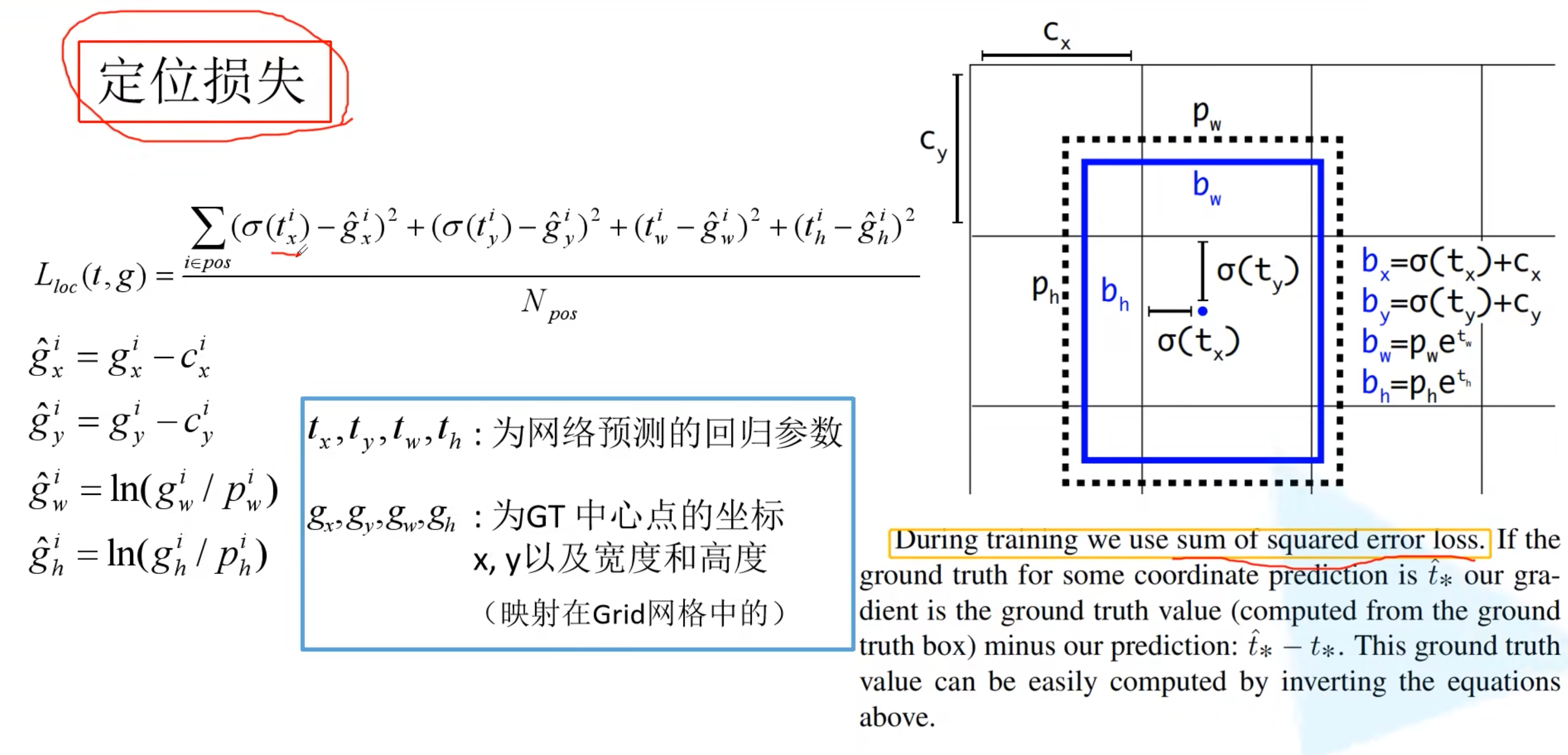
0x03 损失函数
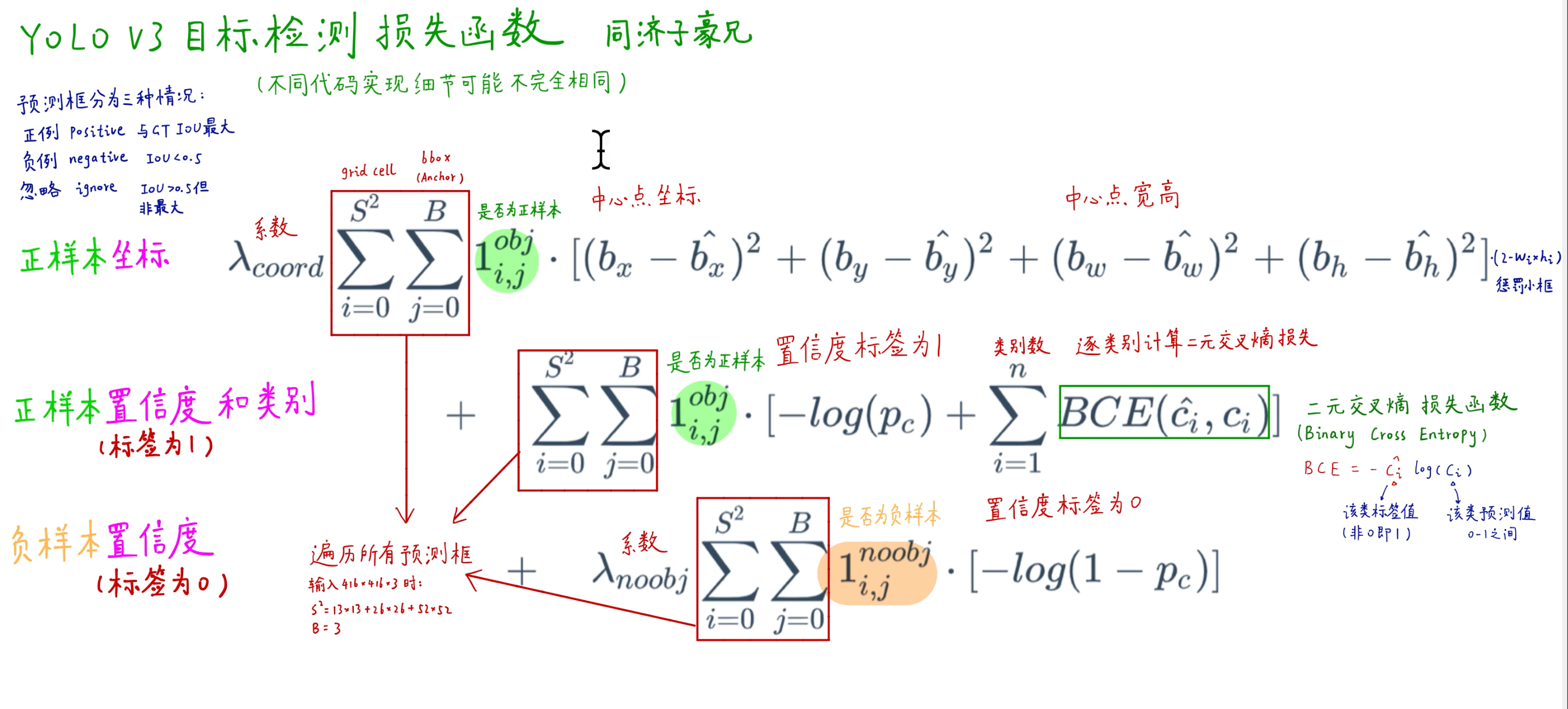
- 正样本对定位、置信度、类别的损失函数都有贡献
- 负样本只对置信度损失函数有贡献









评论 (0)