

0x00 亮点
- Mosaic图像增强
- SPP模块
- cIoU Loss
- Focal loss——默认不使用
0x01 Mosaic图像增强
- 每个batch随机选取4张图像进行组合
- 优点
- 增加数据的多样性
- 增加目标个数
- BN能一次性统计多张图片的参数——batch size越大,越接近整个数据集的均值和方差
0x02 SPP
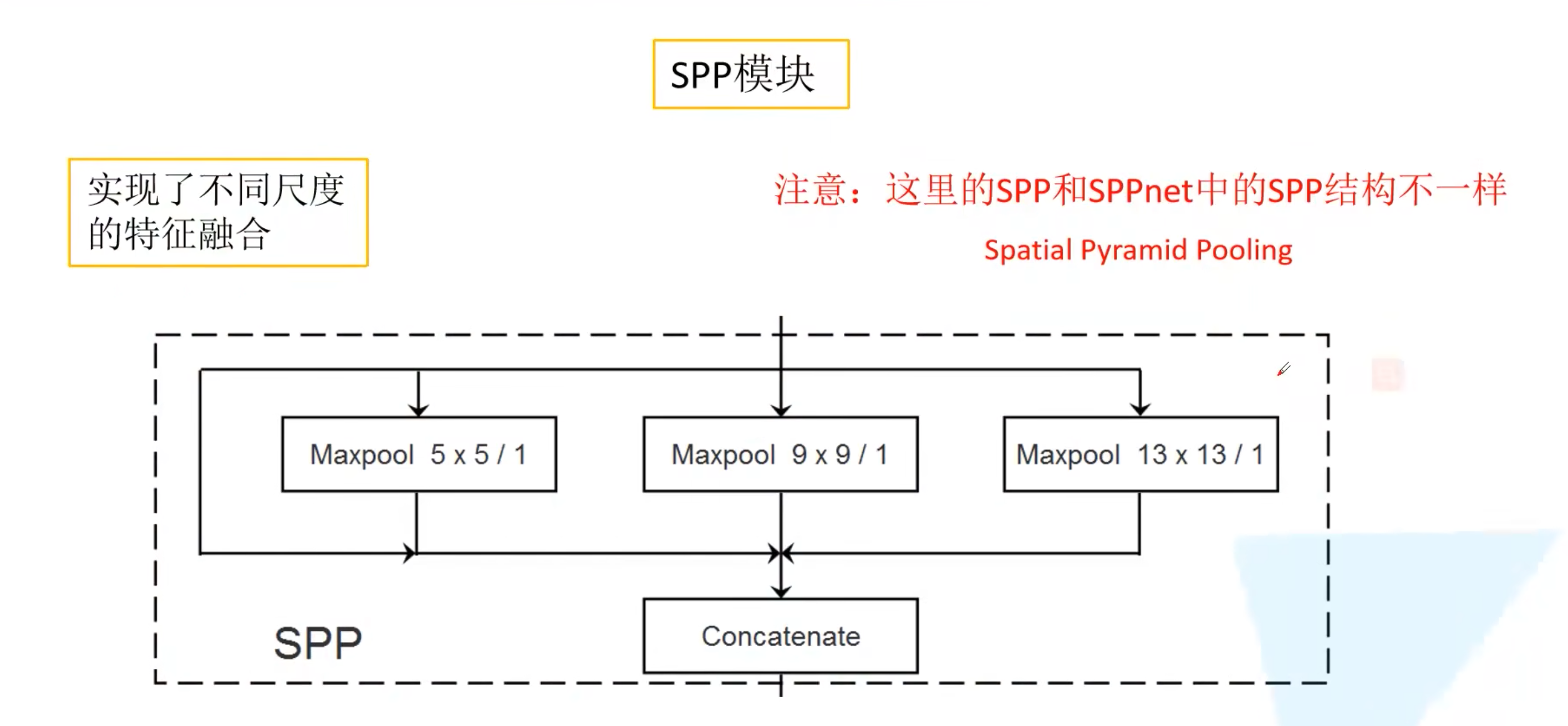
- 借鉴了SPPNet
- 在第一个尺度(32倍下采样)前加入的SPP结构
- 4条并行路线,3个池化层+1个原始输入,输出的feature map宽高、通道数一样,最后再做concat
0x03 CIoU损失
首先要介绍一下定位损失的发展:
L2 Loss -> IoU Loss -> GIoU Loss -> DIoULoss -> CIoU Loss
1. L2 Loss

计算两个box中心坐标平方差、宽的平方差、高的平方差,再求和,也就是V3中的定位损失部分
2. IoU Loss
- IoU:

- IoU Loss:

- 也可以是:\(IoU Loss = 1-IoU(A, B)\)
- 可以更好地反映重合程度
- 具有尺度不变形
- 缺点:
- 当不相交时loss为无穷大
- 没有考虑到位置和形状
3. GIoU Loss
Generalized IoU
- GIoU:
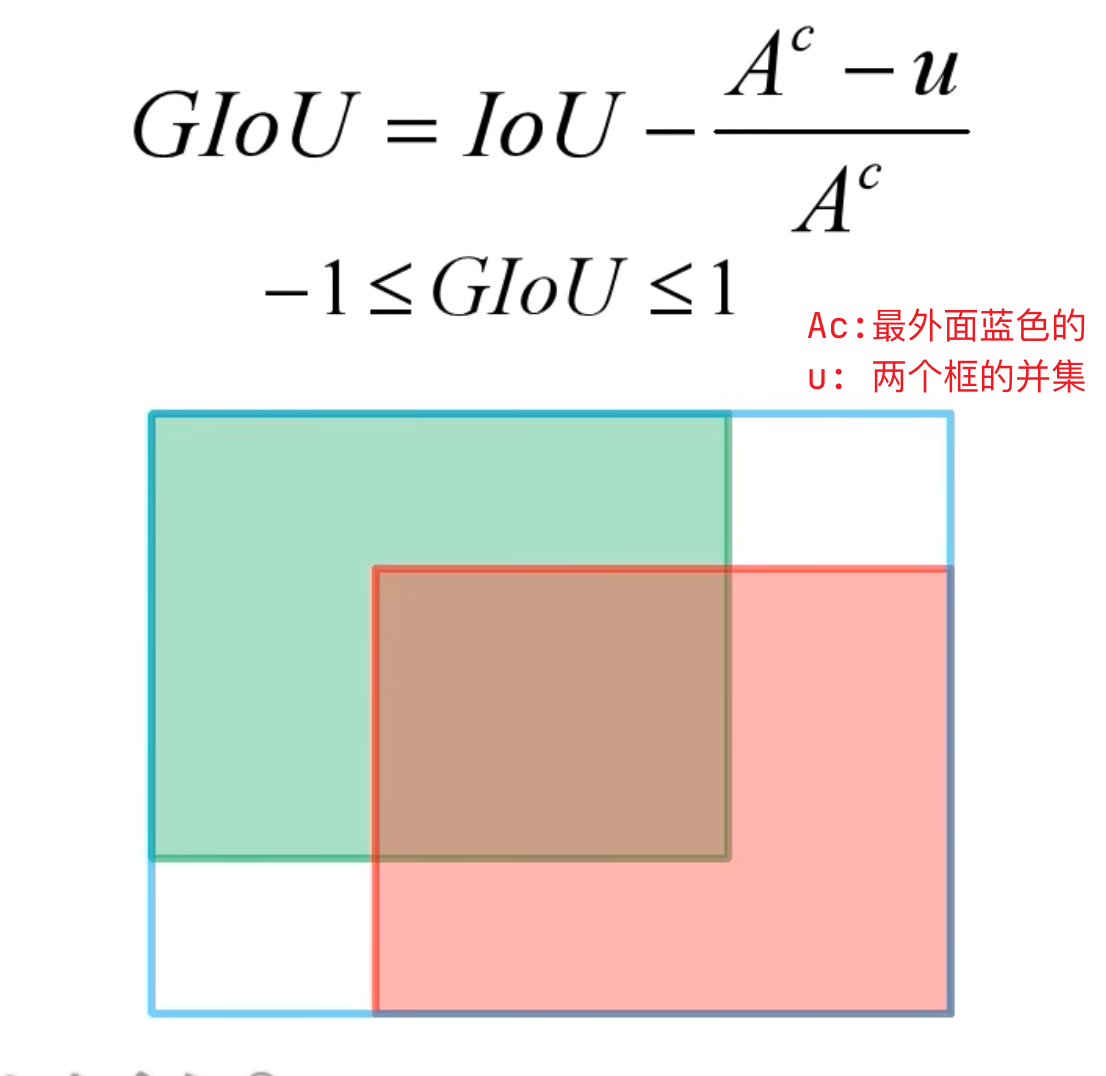
- GIoU Loss:

- 退化:当两个bbox高度或宽度一样,且它们处于水平或垂直方向时,就会退化为GIoU
- 缺点:
- 计算比较复杂,收敛慢
- 定位精度还是比较差
4. DIoU Loss
- 提出背景:

上面三种情况计算处理的IoU和GIoU都是一样的
- DIoU:
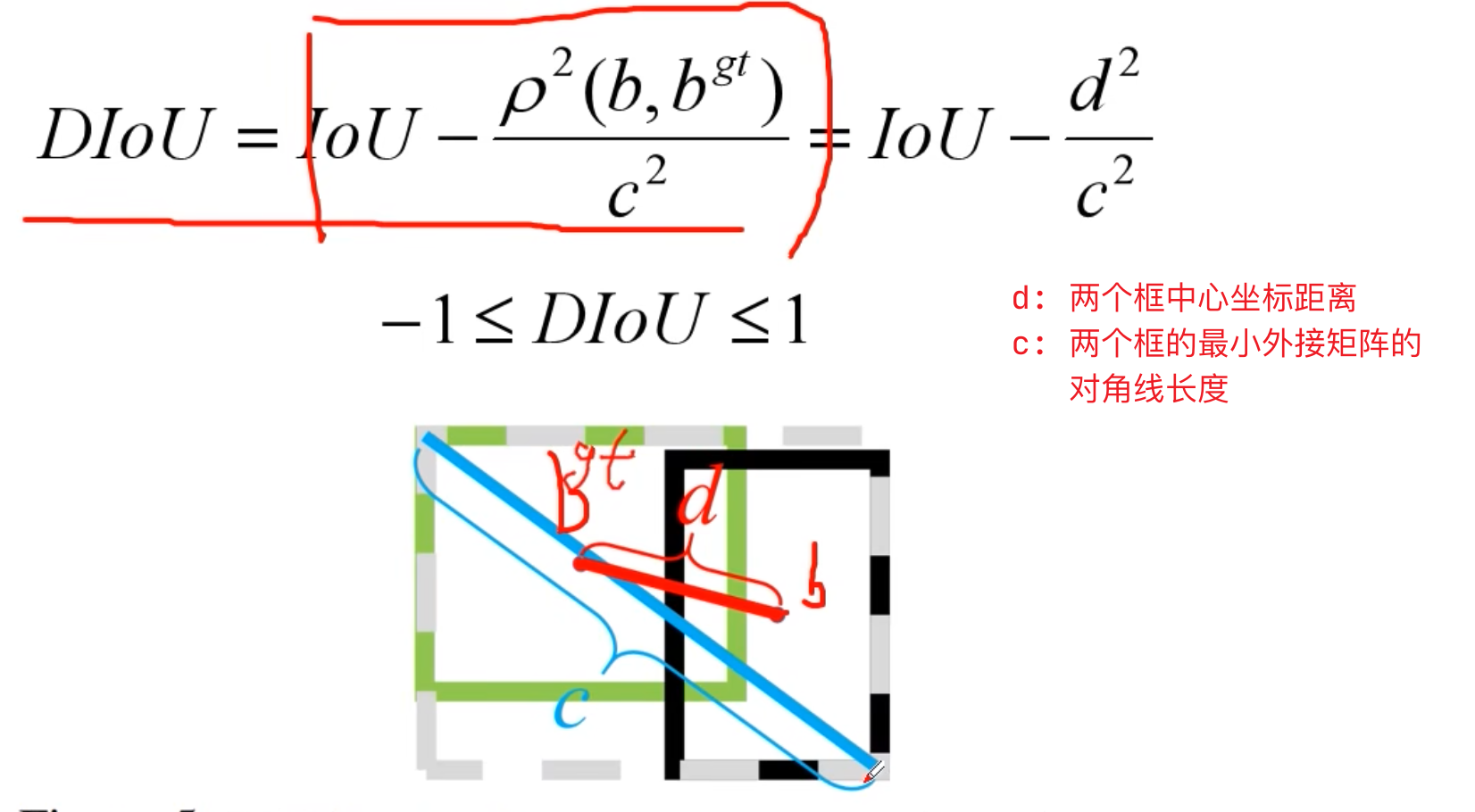
- DIoU Loss:

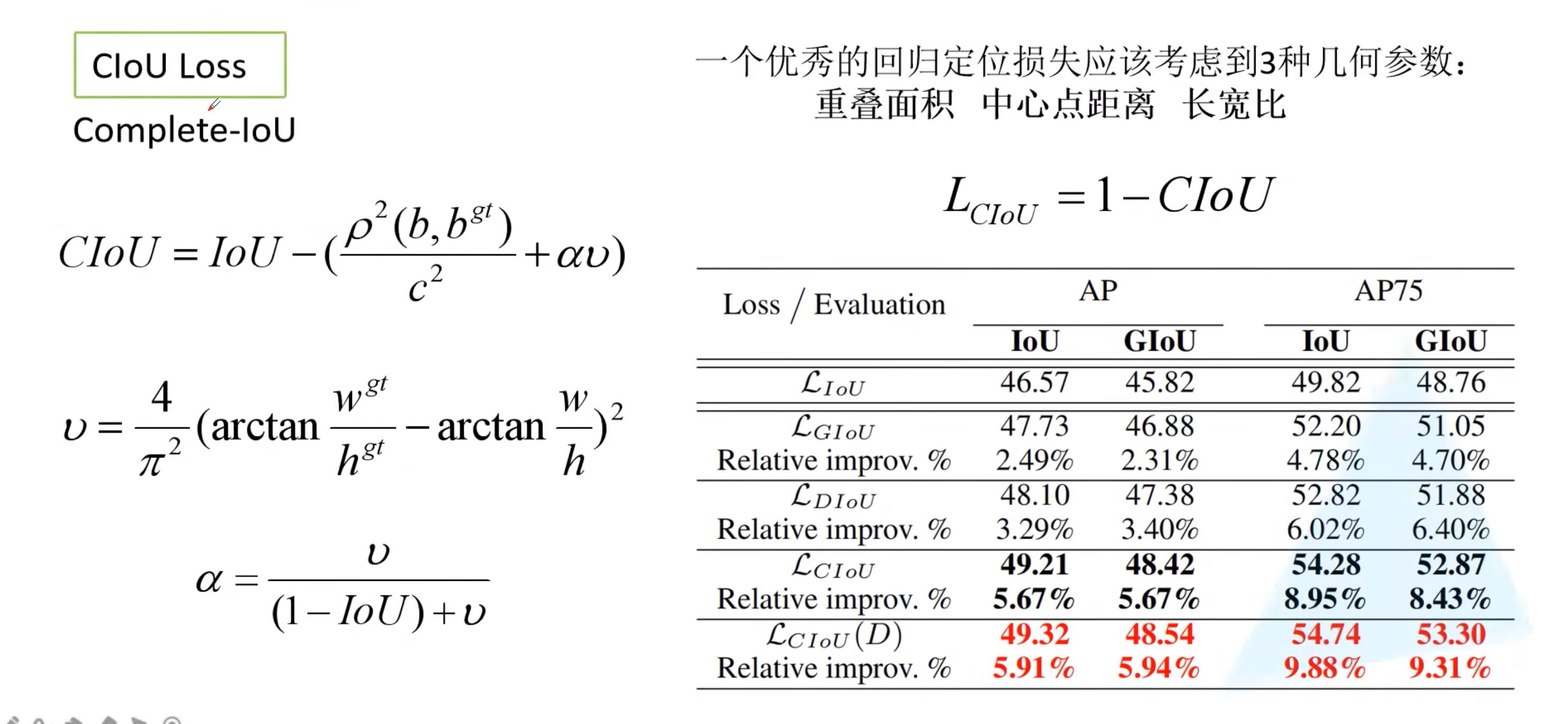
5. CIoU Loss
- CIoU:
- 在DIoU的基础上加上了长宽比
0x04 Focal loss
处理正负样本不平衡问题,主要是用于one-stage
一张图像中能够匹配到目标的候选框(也就是正样本)个数一般只有十几个或几十个,而没有匹配到的候选框(负样本)大概有1w-10w个。在这1w-10w个未匹配到目标的候选框中大部分都是简单易分的负样本(对训练网络起不到什么作用,但由于数量太多会淹没掉少量但有助于训练额度样本)
样本不均衡问题可分为两种:
- 样本类别不均衡:指一个数据集中,各类别样本的比例不均衡。很多贴近实际场景的数据集,样本类别的分布通常是长尾的,即存在很多类别的样本数量很少

样本难易度不均衡:在一个数据集中,(同一类别下)样本的难易往往是不同的,对于分类任务,一个分类器的好坏主要取决于其在困难样本上的性能。Focal Loss处理的就是这个问题
- Focal loss给不同置信度的样本的Loss赋予不同的权重,置信度越低权重越大,隐式地增加困难样本的权重
- Focal loss在交叉熵的基础上乘了个调制系数
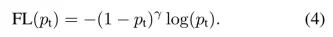
(1-p_t)^r用来调整不同难度样本的权重
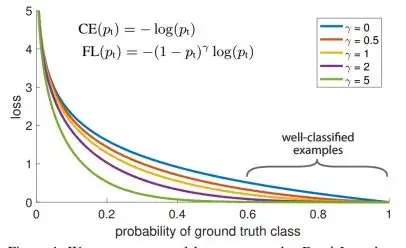
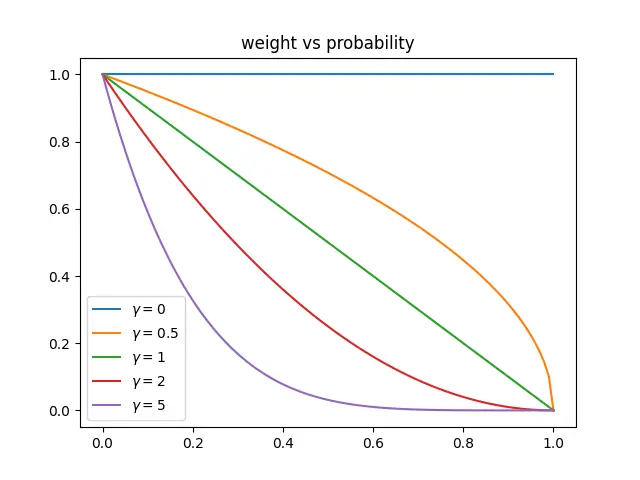
- 调制系数函数图像如图,其为置信度的减函数,样本的置信度越接近1(即样本越简单),调制系数越小(即该样本Loss的权重也就越小);反之,样本置信度越接近0(即样本越困难),调制系数越大(即样本Loss的权重也越大)。举例,一个简单样本E1置信度为0.9,一个困难样本H1置信度为0.1。当使用交叉熵损失时,E1和H1的相对权重相等;当使用𝛾 =5的focal loss时,E1的调制系数: (1−0.9)5=1𝑒−5 ,H1的调制系数: (1−0.1)5=0.59 ,H1和E1的相对权重为5.9e4!!!!
- 𝛾 调节样本权重随着置信度上升衰减的剧烈程度:𝛾越大,衰减越快,相同置信度的简单样本的相对权重越小;反之同理。当 𝛾 为0时,focal loss退化为交叉熵,不同难度样本的相对权重相等








评论 (0)