

Ⅰ. Ubuntu下训练+部署
1. 环境
- TensorFlow:2.4.0
- TensorRT:7.2.2.3
2.官方例程路径
/usr/local/TensorRT-7.2.2.3/samples/python/end_to_end_tensorflow_mnist/model.py
/usr/local/TensorRT-7.2.2.3/samples/python/end_to_end_tensorflow_mnist/sample.py3.model.py代码说明
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
# 数据集处理
def process_dataset():
# Import the data
(x_train, y_train),(x_test, y_test) = tf.keras.datasets.mnist.load_data() # 下载数据集
x_train, x_test = x_train / 255.0, x_test / 255.0 # 数据归一化
# Reshape the data
NUM_TRAIN = 60000 # 训练集中样本个数
NUM_TEST = 10000 # 测试集中集中样本个数
x_train = np.reshape(x_train, (NUM_TRAIN, 28, 28, 1)) # 将训练集样本的 shape reshape 成 [28, 28, 1]
x_test = np.reshape(x_test, (NUM_TEST, 28, 28, 1)) # 将测试集样本的 shape reshape 成 [28, 28, 1]
return x_train, y_train, x_test, y_test
# 构建 LeNet5 模型
def create_model():
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.InputLayer(input_shape=[28,28, 1]))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(512, activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(10, activation=tf.nn.softmax))
# 编译模型--优化方法用 Adam,损失函数使用 sparse_categorical_crossentropy
# 【注】独热编码用 categorical_crossentropy,数字编码用 sparse_categorical_crossentropy
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
# 保存模型到.pb文件
def save(model, filename):
# First freeze the graph and remove training nodes.
output_names = model.output.op.name # 得到输出名称
sess = tf.keras.backend.get_session()
# 将 GraphDef 对象中的变量转化为常量
frozen_graph = tf.graph_util.convert_variables_to_constants(sess, sess.graph.as_graph_def(), [output_names])
# 删除不需要进行推理的节点
frozen_graph = tf.graph_util.remove_training_nodes(frozen_graph)
# Save the model
with open(filename, "wb") as ofile:
ofile.write(frozen_graph.SerializeToString())
def main():
x_train, y_train, x_test, y_test = process_dataset() # 加载样本
model = create_model() # 创建模型
# Train the model on the data
model.fit(x_train, y_train, epochs = 5, verbose = 1) # 训练模型
# Evaluate the model on test data
model.evaluate(x_test, y_test) # 测试模型
save(model, filename="models/lenet5.pb") # 将模型冻结为 .pb 文件,这里的model文件夹需要提前建好
if __name__ == '__main__':
main()以上代码中除了保存模型部分之外都是一些常规操作,这里不再赘述。对于 save(model, filename) 函数,它的具体步骤如下:
- 获取 GraphDef 对象;
- 找到需要导出的节点 output_names;
- 使用 convert_variables_to_constants 方法将 GraphDef 对象中的变量转化为常量,并返回一个新的 GraphDef;
- 删除不需要进行推理的节点;
- 序列化保存到磁盘。
在终端中运行model.py脚本
python model.py可能出现的报错:
(1)Exception has occurred: TypeError
Exception has occurred: TypeError
Keras symbolic inputs/outputs do not implement `op`. You may be trying to pass Keras symbolic inputs/outputs to a TF API that does not register dispatching, preventing Keras from automatically converting the API call to a lambda layer in the Functional Model.原因:这应该是TensorRT官方例程对TensorFlow2.0不友好,还停留在1.x
解决方法:将代码中的
import tensorflow as tf改为
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()(2)Exception has occurred: FileNotFoundError
Exception has occurred: FileNotFoundError
[Errno 2] No such file or directory: 'models/lenet5.pb'原因:没有手动创建models文件夹
解决方法:在model.py同级目录下手动创建models文件夹
4. 将.pb文件转换为.uff文件
cd models
convert-to-uff lenet5.pb -o lenet5.uff输出:
Loading lenet5.pb
NOTE: UFF has been tested with TensorFlow 1.15.0.
WARNING: The version of TensorFlow installed on this system is not guaranteed to work with UFF.
UFF Version 0.6.9
=== Automatically deduced input nodes ===
[name: "input_1"
op: "Placeholder"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "shape"
value {
shape {
dim {
size: -1
}
dim {
size: 28
}
dim {
size: 28
}
dim {
size: 1
}
}
}
}
]
=========================================
=== Automatically deduced output nodes ===
[name: "dense_1/Softmax"
op: "Softmax"
input: "dense_1/BiasAdd"
attr {
key: "T"
value {
type: DT_FLOAT
}
}
]
==========================================
Using output node dense_1/Softmax
Converting to UFF graph
DEBUG: convert reshape to flatten node
DEBUG [/home/linjc/anaconda3/envs/dl/lib/python3.8/site-packages/uff/converters/tensorflow/converter.py:143] Marking ['dense_1/Softmax'] as outputs
No. nodes: 13
UFF Output written to lenet5.uff可以看到输入层名称为input_1,输出层名称为dense_1/Softmax,记住这两个,后面会用到。
可能出现的报错:
(1)AttributeError: module ‘tensorflow’ has no attribute ‘gfile’
原因:TensorFlow2.x将 tf.gfile 改成 tf.io.gfile了,TensorRT官方例程没有更新
解决方法:修改~/anaconda3/envs/dl/lib/python3.8/site-packages/uff/converters/tensorflow/conversion_helpers.py脚本,将其中的
with tf.gfile.GFile(frozen_file, "rb") as frozen_pb:
graphdef.ParseFromString(frozen_pb.read())
return from_tensorflow(graphdef, output_nodes, preprocessor, **kwargs改为
with tf.io.gfile.GFile(frozen_file, "rb") as frozen_pb:
graphdef.ParseFromString(frozen_pb.read())
return from_tensorflow(graphdef, output_nodes, preprocessor, **kwargs5.sample代码说明
from random import randint
from PIL import Image
import numpy as np
import pycuda.driver as cuda
# This import causes pycuda to automatically manage CUDA context creation and cleanup.
import pycuda.autoinit
import tensorrt as trt
import sys, os
sys.path.insert(1, os.path.join(sys.path[0], ".."))
import common
# You can set the logger severity higher to suppress messages (or lower to display more messages)
# 实现日志记录接口,TensorRT通过这个接口报告error、warn、info级别的消息
TRT_LOGGER = trt.Logger(trt.Logger.WARNING) # 抑制info级消息,仅报告warn和error级别
# 设置网络信息和样本信息
class ModelData(object):
MODEL_FILE = "lenet5.uff" # 网络模型名称
INPUT_NAME ="input_1" # 网络输入层名称
INPUT_SHAPE = (1, 28, 28) # 样本 shape,这里的顺序是(channels, height, width)
OUTPUT_NAME = "dense_1/Softmax" # 网络输出层名称
# 建立引擎
def build_engine(model_file):
# For more information on TRT basics, refer to the introductory samples.
# 创建 builder、 network、 parser
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.UffParser() as parser:
builder.max_workspace_size = common.GiB(1) # 为 builder 指定一个最大的 workspace 空间
# Parse the Uff Network
parser.register_input(ModelData.INPUT_NAME, ModelData.INPUT_SHAPE) # 注册网络的输入
parser.register_output(ModelData.OUTPUT_NAME) # 注册网络的输出
parser.parse(model_file, network) # 解析网络
# Build and return an engine.
return builder.build_cuda_engine(network) # 返回构建好的引擎
# Loads a test case into the provided pagelocked_buffer.
# 加载并处理测试图片
# 因为样本名称是从 0.pgm 到 9.pgm,所以 case_num=randint(0, 9)
def load_normalized_test_case(data_paths, pagelocked_buffer, case_num=randint(0, 9)):
[test_case_path] = common.locate_files(data_paths, [str(case_num) + ".pgm"], err_msg="Please follow the README in the mnist data directory (usually in `/usr/src/tensorrt/data/mnist`) to download the MNIST dataset")
# Flatten the image into a 1D array, normalize, and copy to pagelocked memory.
# Flatten 该图像成为一个 1 维数组,然后归一化,并 copy 到主机的 pagelocked 内存中
img = np.array(Image.open(test_case_path)).ravel()
np.copyto(pagelocked_buffer, 1.0 - img / 255.0)
return case_num
def main():
# 这里返回的是存放样本的文件夹的路径
data_paths, _ = common.find_sample_data(description="Runs an MNIST network using a UFF model file", subfolder="mnist")
# 这里返回的是存放模型 .uff 文件的文件夹的路径
model_path = os.environ.get("MODEL_PATH") or os.path.join(os.path.dirname(__file__), "models")
# 这里返回的是模型 .uff 文件的路径
model_file = os.path.join(model_path, ModelData.MODEL_FILE)
with build_engine(model_file) as engine:
# Build an engine, allocate buffers and create a stream.
# For more information on buffer allocation, refer to the introductory samples.
inputs, outputs, bindings, stream = common.allocate_buffers(engine) # 将数据从主机传输到 GPU
with engine.create_execution_context() as context: # 通过引擎得到 context
case_num = load_normalized_test_case(data_paths, pagelocked_buffer=inputs[0].host) # 读取测试样本,并归一化
# For more information on performing inference, refer to the introductory samples.
# The common.do_inference function will return a list of outputs - we only have one in this case.
# 对测试样本进行推理,返回一个列表,此例中列表内只有一个元素
[output] = common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
# 如果有多个 input/output 节点,则使用 common.do_inference_v2 函数
pred = np.argmax(output)
print("Test Case: " + str(case_num))
print("Prediction: " + str(pred))
if __name__ == '__main__':
main()
【注】因为创建引擎是很耗时的,所以强烈建议将引擎保存下来:
serialized_engine = engine.serialize() # 序列化引擎
# 写入文件
with open(engine_path, 'wb') as f:
f.write(serialized_engine)这样一来,我们就不用重复创建引擎了,只需要加载即可:
# 从文件读取引擎并反序列化
with open(engine_path, 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())在推断过程中,我们使用了 common.do_inference 函数,它的具体步骤如下:
- 将输入的数据从主机传输到 GPU;
- 通过异步执行去做推断;
- 将推断的结果从 GPU 传回主机;
- 将 stream 同步。
其代码如下:
# This function is generalized for multiple inputs/outputs.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# Transfer input data to the GPU.
# 将数据移动到 GPU
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
# 执行异步推断
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
# 将结果从 GPU 写回到 host 端(GPU --> 主机)
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
# 同步 stream
stream.synchronize()
# Return only the host outputs.
# 返回主机的输出结果
return [out.host for out in outputs在终端中运行sample.py脚本
python sample.py输出结果:
Test Case: 7
Prediction: 7可能出现的报错:
(1)Exception has occurred: ModuleNotFoundError
Exception has occurred: ModuleNotFoundError
No module named 'pycuda'原因:没有安装pycuda模块
解决方法:安装pycuda模块
pip install pycuda(2)Exception has occurred: FileNotFoundError
Exception has occurred: FileNotFoundError
Could not find 7.pgm. Searched in data paths: ['/usr/src/tensorrt/data/mnist']
Please follow the README in the mnist data directory (usually in `/usr/src/tensorrt/data/mnist`) to download the MNIST dataset原因:/usr/src/tensorrt/data/mnist下没有MNIST数据集
解决方法:下载数据集放入/usr/src/tensorrt/data/mnist目录下,可以使用/usr/local/TensorRT-7.2.2.3/data/mnist/download_pgms.py这个脚本下载,也可以使用我下面提供的(脚本经常出现503错误)
Ⅱ. Windows下部署
上文中我们在Ubuntu下训练得到了uff模型,本节介绍如何在windows环境下部署这一模型。
1.环境:
- TensorFlow:2.4.0
- TensorRT:7.2.1.6
2.复制模型文件
将Ubuntu下的lenet5.uff文件复制到windows下的D:\TensorRT-7.2.1.6\data\mnist路径下,为了防止与原先的模型混淆,这里我们将其重命名为len5.uff
3.打开sampleUffMNIST例程
路径:D:\TensorRT-7.2.1.6\samples\sampleUffMNIST
4.修改例程
将
samplesCommon::UffSampleParams initializeSampleParams(const samplesCommon::Args& args)
{
samplesCommon::UffSampleParams params;
if (args.dataDirs.empty()) //!< Use default directories if user hasn't provided paths
{
params.dataDirs.push_back("data/mnist/");
params.dataDirs.push_back("data/samples/mnist/");
}
else //!< Use the data directory provided by the user
{
params.dataDirs = args.dataDirs;
}
params.uffFileName = locateFile("lenet5.uff", params.dataDirs);
params.inputTensorNames.push_back("in");
params.batchSize = 1;
params.outputTensorNames.push_back("out");
params.dlaCore = args.useDLACore;
params.int8 = args.runInInt8;
params.fp16 = args.runInFp16;
return params;
}修改为
samplesCommon::UffSampleParams initializeSampleParams(const samplesCommon::Args& args)
{
samplesCommon::UffSampleParams params;
if (args.dataDirs.empty()) //!< Use default directories if user hasn't provided paths
{
params.dataDirs.push_back("data/mnist/");
params.dataDirs.push_back("data/samples/mnist/");
}
else //!< Use the data directory provided by the user
{
params.dataDirs = args.dataDirs;
}
params.uffFileName = locateFile("len5.uff", params.dataDirs);
params.inputTensorNames.push_back("input_1");
params.batchSize = 1;
params.outputTensorNames.push_back("dense_1/Softmax");
params.dlaCore = args.useDLACore;
params.int8 = args.runInInt8;
params.fp16 = args.runInFp16;
return params;
}其实就是修改了模型、输入、输出层的名称而已。
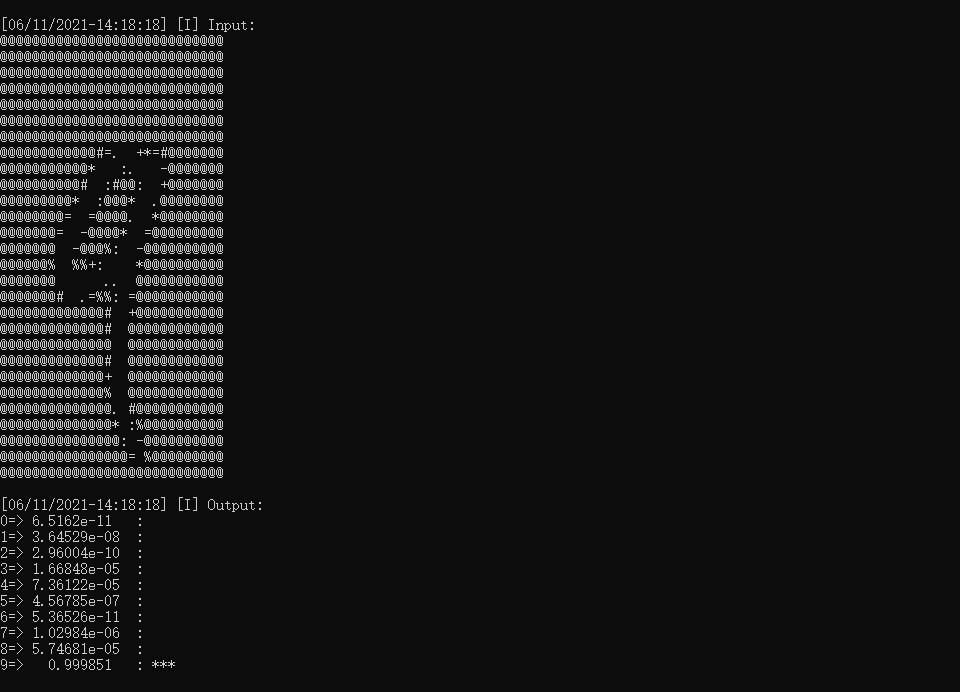
5.编译运行
输出结果如下:
可能出现的错误:
(1)Could not find 0.pgm in data directories:
Could not find 0.pgm in data directories:
data/mnist/
data/samples/mnist/
&&&& FAILED原因:D:\TensorRT-7.2.1.6\data\mnist下没有MNIST数据集
解决方法:下载数据集放入D:\TensorRT-7.2.1.6\data\mnist目录下,可以使用 D:\TensorRT-7.2.1.6\data\mnist mnist\download_pgms.py这个脚本下载,也可以使用我下面提供的(脚本经常出现503错误)
至此,我们就打通了Ubuntu和Windows两个平台下的模型训练和部署。
END
参考:
1. TENSORRT 加速 TENSORFLOW 实现 MNIST 数据集分类详解
2. TensorRT推理加速-基于Tensorflow(keras)的uff格式模型(文件准备)
3. 解决报错 AttributeError: module ‘tensorflow’ has no attribute ‘gfile’








评论 (0)