

0x00 Abstract
以往的目标检测网络是在分类基础上完成目标检测,最典型的就是RCNN系列,这种也叫two- stage。YOLO是一个新的目标检测方式(将目标检测作为一个回归问题来处理),所以属于one-stage。YOLO的意思就是:You Only Look Once。
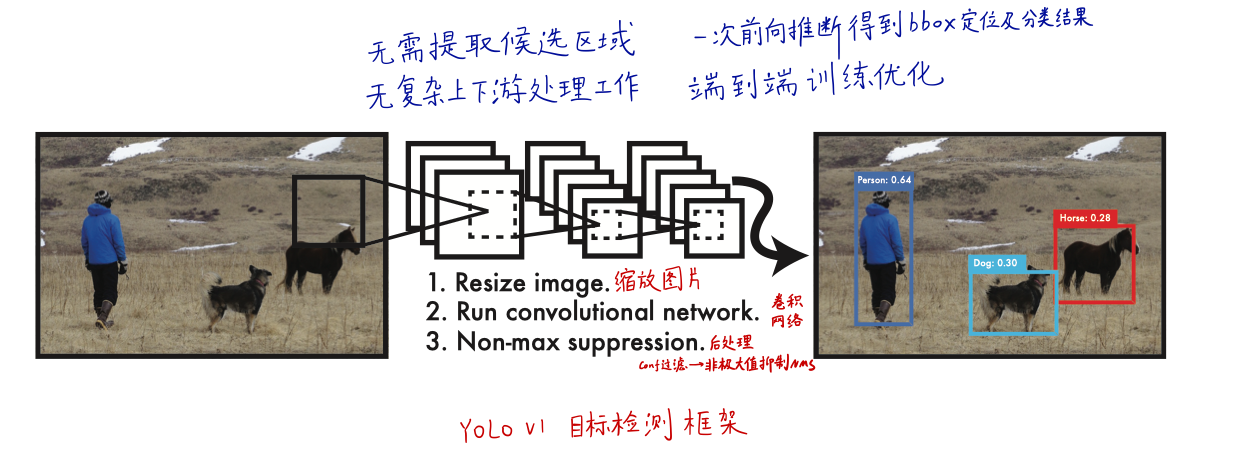
YOLO将分类和边框预测作为回归问题来处理,它是端到端(end-to-end) 的,也就是说输入图像经过CNN之后,直接得到分类和定位结果。
YOLO是全局获取图像信息,整体操作(DPM、RCNN每次都只是检测框里的,框外的不检测,管中窥豹),由于是一个单独的网络,能够直接优化。
检测速度很快(文章中多次出现,这也是YOLO系列最大的亮点),速度:45FPS(实时:30FPS),作者还训练了一个更快的版本Fast YOLO,可以达到155FPS,并且可以达到其他实时目标检测网络的2倍mAP。
对比其他网络:定位错误多、背景误判少(主要是定位错误,误判少)。特点:通用性强。对于艺术作品的的检测效果明显优于DPM、RCNN(体现了YOLO的泛化能力强)
0x01 Introduction
首先是对比了DPM和RCNN。DPM是用滑动窗口的方式进行检测的,RCNN是要先生成候选区域(使用selective search)。它们的缺点是网络的两步是独立的,要分类训练,这就导致了模型难以优化。
简单介绍一下滑动窗口:采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类(应该是在学习这个东西是目标物还是背景)如下图所示:

但是在实际情况中你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长,这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN(基于区域提议的CNN)的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。
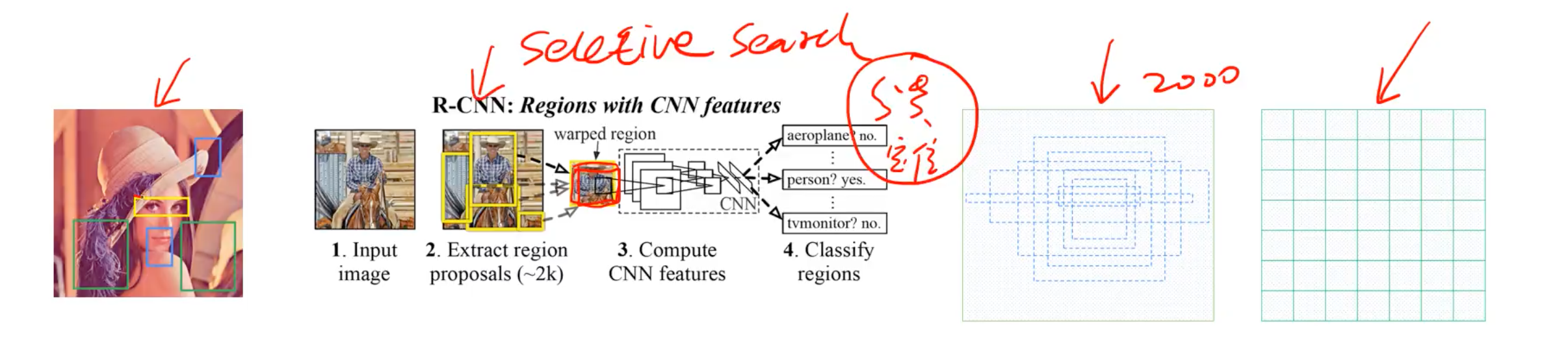
接下来看YOLO的做法:
- 核心就是一步直接完成定位+分类
- 优点:
- 非常快
- mAP是其他实时系统的两倍以上(注意这里对比的实时系统,像Fast RCNN这种非实时的网络,mAP在当时是比YOLO高的)
- 看全局,不需要候选框。例如和RCNN比较:Fast R-CNN由于看不到较大的上下文,因此会将图像中的背景色块误认为是目标对象。与Fast R-CNN相比,YOLO产生的背景错误少于一半
- 泛化性(通用性)强。
- 表现:在自然图像上训练,在艺术图像上识别,表现远远超过DPM和RCNN
- 结论:由于具有较高的泛化性,在遇到新领域、碰到意外输入时,不容易奔溃
- 缺点:
- 准确性较低(相比RCNN)
- 在小对象的识别上不足(例如鸟群):因为分成了7*7个cell,天生就不利于检小对象
0x02 Unified Detection
YOLO把目标检测的“分类+定位”整合到一起,网络使用来自整张图像的特征来预测目标的边界框(end-to-end)
- 同时对图像中所有目标类别的边界框进行预测
- 可以对整张图像及其图像中的目标进行全局分析
- 端到端、实时、高AP(也就是PR曲线围城的面积)
1. 怎么做的?

- 把整幅图像分为S*S个格子(S=7)
- 如果对象的中心点所在某个格子中,那么这个格子就负责检测这个对象
- 每个格子都预测B个bbox,对应的每个bbox也有1个置信度(B=2)
- 也就是说整幅图像有49个格子,98个bbox
- 置信度confidence。当没有对象时Pr为0,有对象Pr为1,IOU就是预测框与真实框的交并比)
\(confidence=Pr(Object)*IOU_{pred}^{true}\)
Pr在训练阶段是非0即1的;在预测阶段代表grid cell中有对象的概率,0-1之间。但是预测阶段不需要分别计算出Pr和IOU各为多少,而是隐式地包含它们。

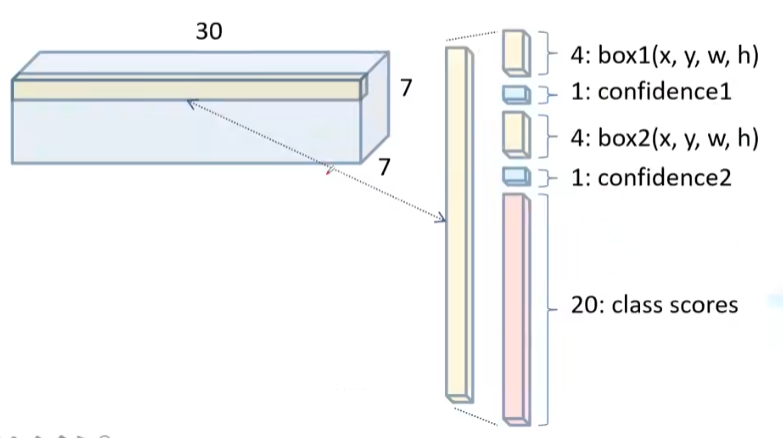
- 每个bbox包括5个预测值:x、y、w、h、confidence
- (x, y):bbox中心点位置,相对的是其所在grid cell的,归一化到0-1之间
- w、h:bbox的宽和高,相对的是整幅图像的,也归一化到0-1之间
- confidence:置信度,当格子里没有对象时为0,有对象时为gtbox和predbox的交并比
- 每个格子同时也预测C个类别(训练使用的数据集时PASCAL VOC,所以C=20)
- 概率值通过条件概率计算得到:
\(Pr(Class_i|Object)\)
(解释:在当前bbox已经包含物体的条件下,各类别的概率)
- 每个单元格只预测一组类别的概率(也就是说B个bbox共用)
- 上述概率限制了YOLOv1预测重叠或临近物体的能力,即每个格子仅只能预测一个类别,一共49个格子,YOLO仅仅能预测49个对象。如果图像中的物体超出,则无能为力
- 在测试阶段(也就是最终预测,闭卷考试),将每个bbox的置信度与上面的条件概率相乘,结果就是每个box的特定特定类别的置信度分数,这个分数既编码了该类别出现在box中的概率,又编码了预测框与对象的拟合程度:
- 概率值通过条件概率计算得到:
$$Pr(Class_i|Object)Pr(Object)IOU_{pred}^{true}=Pr(Class_i)*IOU_{pred}^{true} $$
- 最后预测的结果:
S * S * (B * 5 + C)大小的tensor,这里就是7 * 7 * 30,这个tensor就是YOLO的输出:

2. Network Design

- 属于CNN网络,主要分为两部分:
- 卷积层,作用:提取特征。这里有24个卷积层(不包括池化层)
- 全连接层,作用:分类。这里有2个全连接层
- 作者说受到了GoogLeNet网络的启发
- 但是没有使用Inception块,而是简单地用1×1卷积后接3×3卷积替代
复习一下1×1卷积:

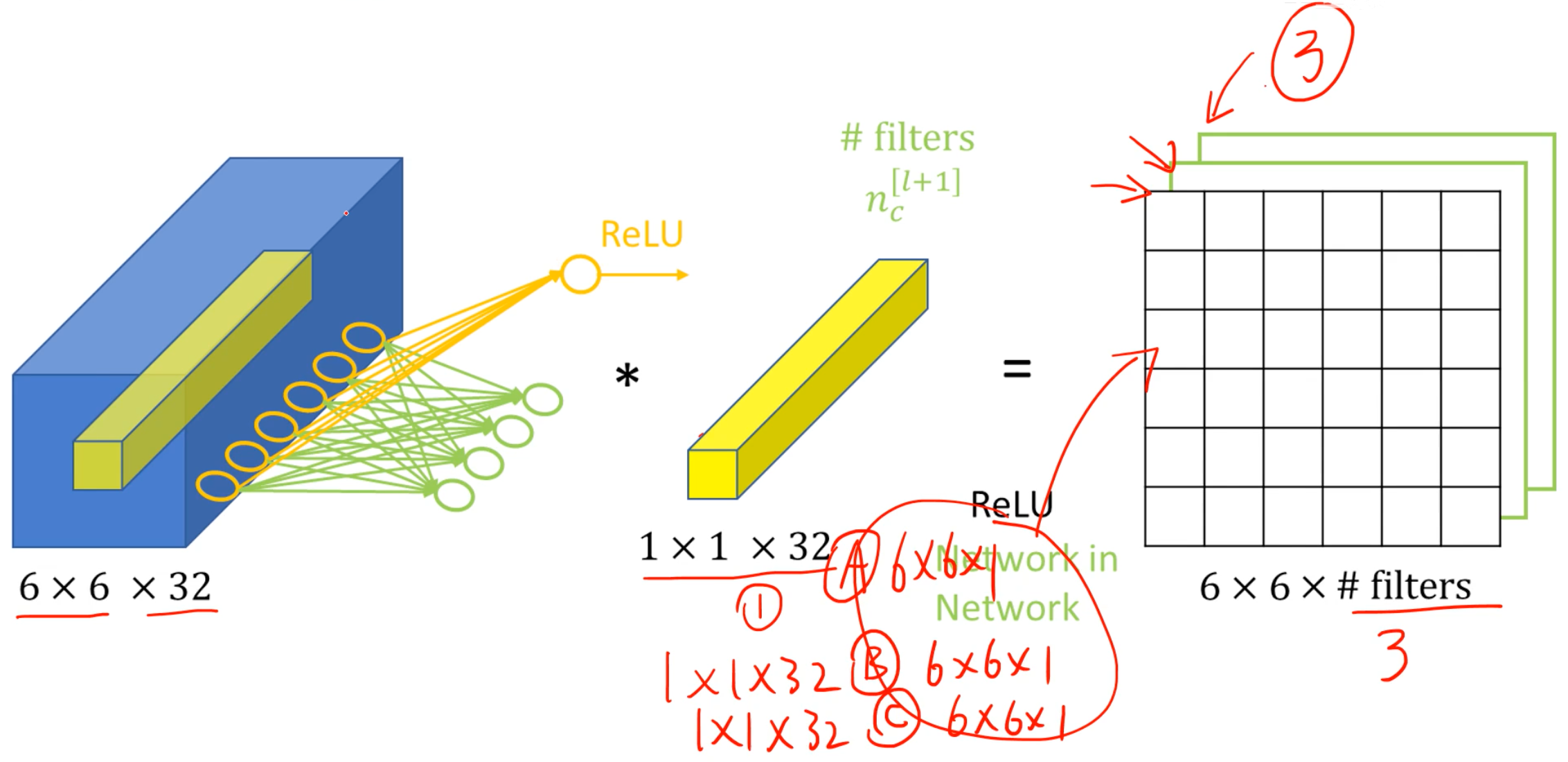
- 通道数必须和原始的一样
- 结果W、H不变,通道数与使用了多少个1×1卷积核一样
- 作用:
- 降维,减少运算量(当然也可以升维)。这里是先用1×1卷积降维,再用3×3卷积
- 跨通道信息传递
如果不使用1×1来降维,而是直接用3×3卷积核降维,运算量会大大增加:
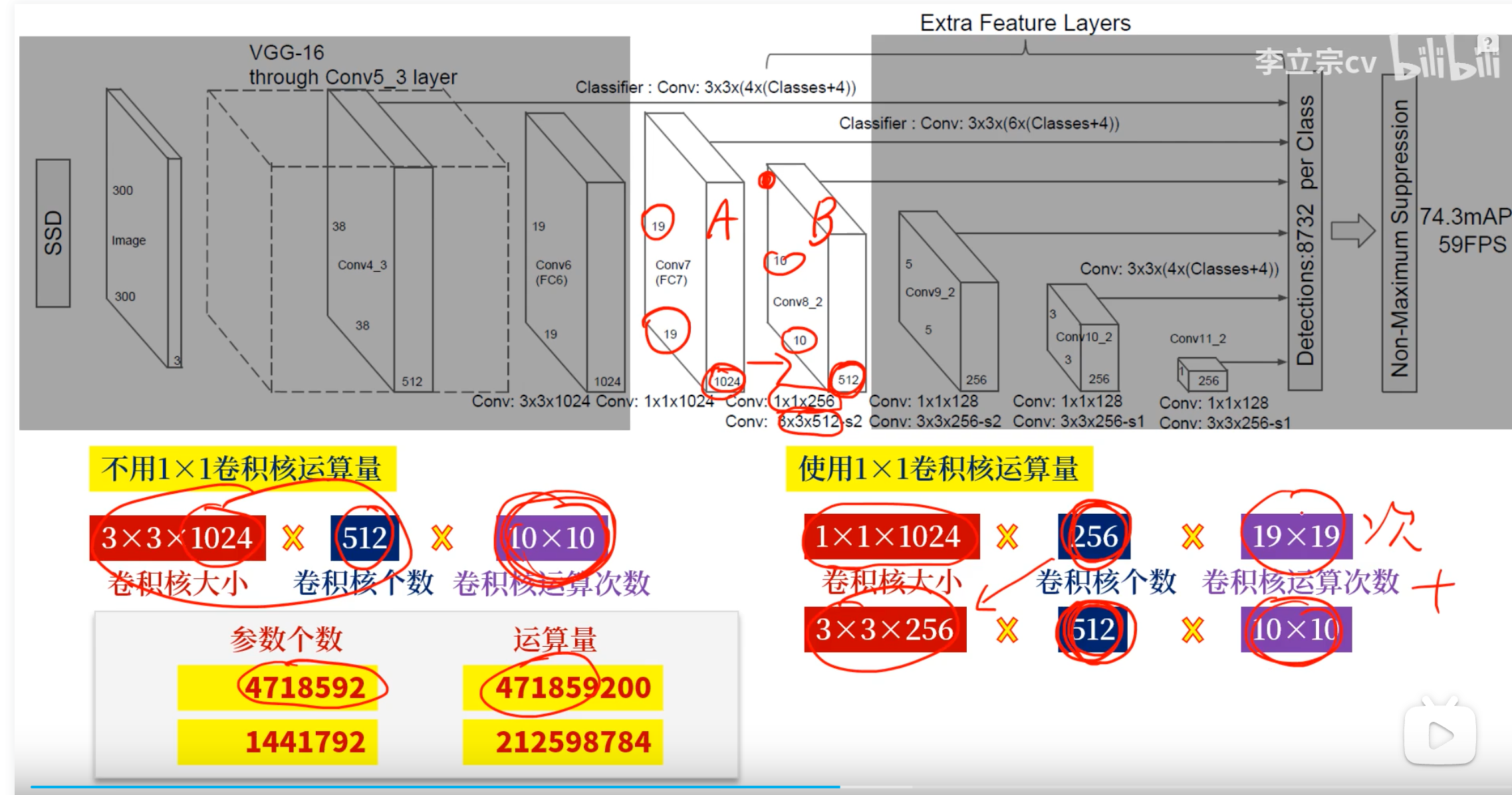
上图SSD网络,如果想从A到B有两种方法:
1. 直接用3×3卷积核
2. 先用1×1卷积核,再用3×3卷积核
可以看出,第2种方法的参数更少,运算量更少
- 在ImageNet数据集上预训练卷积层,训练的时候使用的图像分辨率是检测的一半(训练用224×224)
- Faster YOLO
- 用了更少的卷积层核卷积核(9层)
- 除了网络的size,训练和测试用的其他参数与YOLO一样
- YOLO的最终输出:7x7x30的tensor
3. Training
- 在ImageNet上预训练
- 一开始用了前20个卷积层+1个均值池化+1个全连接层
- 训练了约一周
- ImageNet2012作为验证集,top-5准确率88%
- 接着根据任少卿等人的研究经验,在预训练网络中添加了卷积层和全连接层,以提高性能
- 添加了4层卷积层+2层全连接层,并随机初始化这些层的权重(所以最后的网络是24层)
- 由于检测通常需要细粒度的信息,把输入从224×224调整到448×448
- 最后的层同时预测了类别概率和bbox坐标
- 对bbox做了归一化:
- (x, y):bbox中心点位置,相对的是其所在grid cell的,归一化到0-1之间
- w、h:bbox的宽和高,相对的是整幅图像的,也归一化到0-1之间
- 激活函数:
- 网络的最后一层使用线性激活函数,其他层使用leaky ReLU
- leaky ReLU:
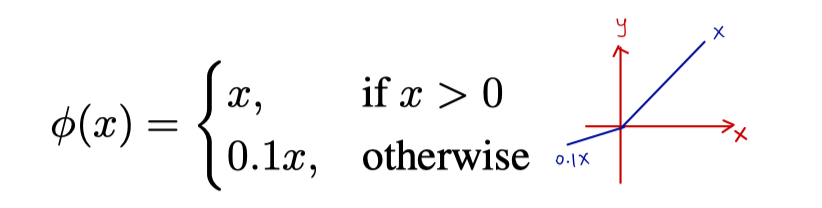
- 损失函数:平方和误差
- 优点:易于优化(好求导)
- 缺点:
- 分类和定位误差的权重是一样的
- 大多数格子没有对象,这会导致这些cell的“置信度”趋向0,然后会压制哪些有对象的cell的梯度,从而使模型不稳定、在训练早期就发散了
- 大尺寸的bbox和小尺寸的bbox具有相同权重,但是我们希望小框带来的误差更大
- 改进:
- 加强bbox定位误差损失,给予高权重:5
- 削弱不包含对象的bbox的置信度的损失,给予低权重:0.5
- 使用bbox宽高的平方根来计算误差
- 例如大框的宽为16,小框宽为4,大框偏了4才变成了20,小框的宽偏了4,变成了两倍,虽然都是偏了相同的距离,但是明显小框受到的影响更大;若换成平方根就将他们之间的影响凸显出了,大框宽的平方根是4,小框为2;大框宽的偏移量为 √20-√16=2√5-4=0.4721,小框宽的偏移量为√8-√4=2√2-2=0.8284。很明显小框的变化大于大框,可以更好的凸显变化;这里只是举例说明。


(这样大框尺寸发生变化时,比小框带来的影响会小点)
- YOLO的每个格子都会预测B个bbox。但是在训练的时候,只会取其中一个bbox,取的就是那个IOU最大的,其他的丢弃掉。这会导致B个bbox逐渐特异化,使得每个框都逐渐聚焦至特定的形状或长宽比
- 包含物体的cell,有2个predictor(B=2)
- 1个负责预测(这个bbox具有更大的IOU)
- 另一个不负责
- 不包含对象的cell
- 包含物体的cell,有2个predictor(B=2)
- 只有当网格中有对象时,才会对分类错误进行惩罚(就是之前那个条件概率)
- 只有当该predictor对某个对象负责时,才会惩罚这个bbox的坐标错误(一个cell有2个predictor,只有1个负责预测)
- 超参数:
- 在PASCAL VOC数据集、测试集上训练135个epoch
- 同时训练VOC2007/2012
- batch-size:64
- momentum(动量):0.9,作用:冲过局部最优解、鞍点
- decay(权重衰减):0.0005,作用:防止过拟合
- 学习策略:
- 最开始的几个epoch学习率从0.001缓慢地增加到0.01。如果一开始就使用高学习率,模型通常会因为不稳定的梯度而发散
- 前75个epoch使用0.01,再用0.001训练30个epoch,最后再用0.0001训练30个eppch
- 使用了dropout
- 防止过拟合
- 概率:0.5
- 在第一层全连接层之后
- 数据增强
- 随机缩放和平移
- 在HSV色彩空间中随机调整图像的曝光度和饱和度

4. Inference
- 会预测出98个bbox,以及每个bbox的类别概率
- NMS:非极大值抑制

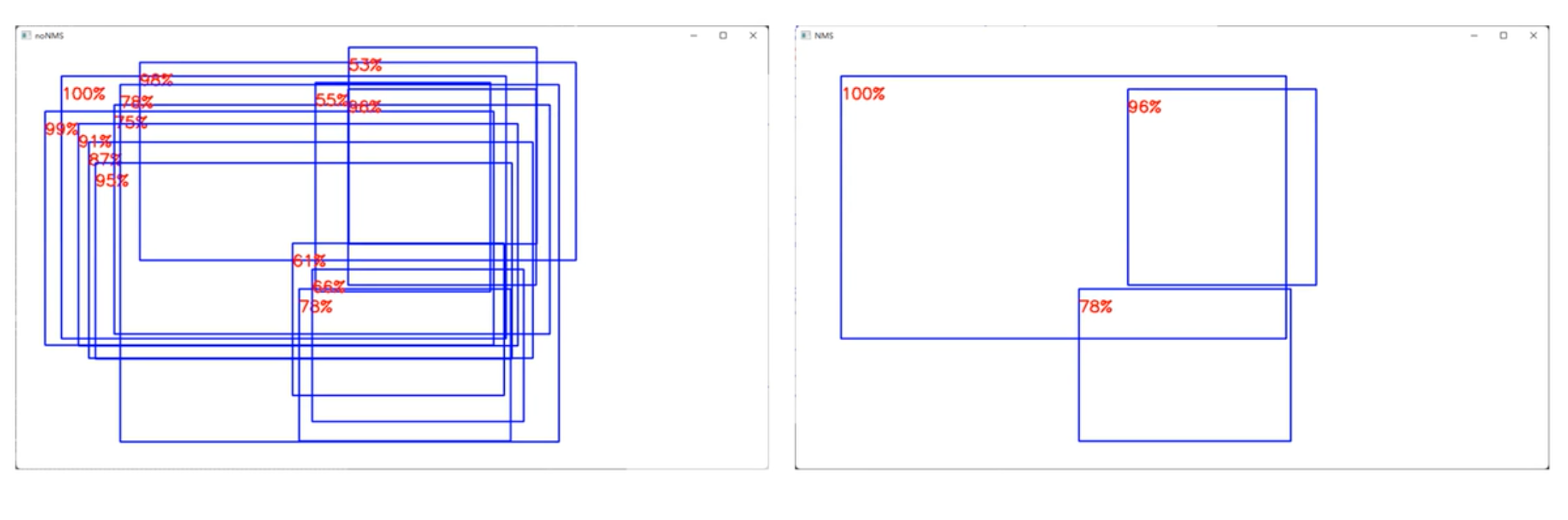
- NMS做法:
- 首先筛选出分数最大的bbox
- 把与上面bbox的IOU比较大的其他bbox去掉(这里会设一个NMS的IOU阈值)
- 再筛选出剩余bbox中分数最大的
- 重复上面的流程
5. Limitations
- 对bbox预测施加了很强的空间约束(分成了7×7个grid cell)
- 每个cell至预测了2个bbox,且只有一个类别
- 空间约束限制了模型可以预测的邻近物体的数量
- 对成群出现的小物体(如鸟群)的检测效果差
- 由于模型时从数据中学习,去预测bbox的,所以难以泛化到新的,不常见的纵横比的对象
- 由于模型包含了多个下采样层,模型使用到的特征的粒度也比较粗
- 在损失函数中,对大bbox和小bbox采取了一致的处理,但是小框带来的错误对IOU带来的影响要大很多
- YOLO的误差主要在定位误差上,即分类正确但是定位偏差较大








评论 (0)