

0x00 Abstract
- 我们提出了一种残差学习框架来解决非常深的神经网络的训练问题
- 明确地重构了学习框架,让网络可以直接学习输入信息与输出信息的差异(即残差),而不必学习一些无关的信息
- 这种残差网络更加容易进行优化,而且随着网络层数的增加,准确率也就增加
- 在ImageNet的数据集中,我们证实了在深度达到152层的残差网络上(相当于VGG net的8倍),但网络的复杂度仍然相对较低
- ILSVRC 2015图像分类第一名
- 在CIFAR-10数据集上构建了100和1000层的模型
- 在诸多计算机视觉任务中,特征提取网络的深度是重中之重。仅仅是通过对于网络深度的增加,让我们在COCO 目标检测数据集上获得了28%的性能提升
- ImageNet目标检测和定位、COCO目标检测和分割任务的第一名
0x01 Introduction
深度卷积神经网络的应用在图像分类领域已经引发了一系列的突破。深度网络很自然地集成了图像中的低/中/高级别的特征信息和分类器,并且是以端到端的形式完成的。
最近的研究也表明网络的深度是非常重要的一部分。由于’深度‘对于网络的重要意义,一个问题开始出现:学习深度的网络就是简单粗暴地堆叠网络的层数吗?面临的障碍有:
- 梯度消失
梯度爆炸但是这两个问题已经可以通过各种权重初始化和中间层的归一化处理来有效解决了,让拥有着数十层深度的网络都可以通过SGD 的方法进行反向传播
- 还有一个问题:网络“退化”
即随着网路层数的增加,模型的准确性开始饱和,然后迅速退化
网络退化不是又过拟合导致的。它是在训练集和测试集上都差,而且是增加更多层数就更差

- 为了解决网络问题,一开始想的一个方案是:

给人的直观感受是这样的训练误差不会高于之前的浅模型(不会更差,大不了上面那一路为0)
但实验结果表明,这种网络效果不佳且难以优化
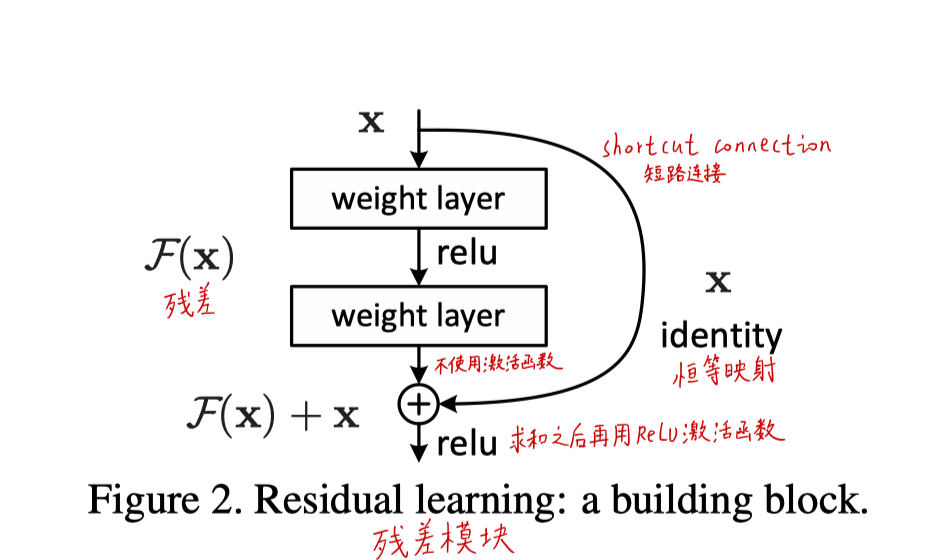
- 残差模块:一条路不变(恒等映射);一条路负责拟合相对于原始网络的残差,去纠正原始网络的偏差,而不是让整体网络去拟合全部的底层映射,这样网络只需要纠正偏差
- shortcut connection短路连接(捷径连接)也可以叫skip connection跳跃连接、identity恒等映射,是一个东西
- 原先没有短路的话,模型是直接拟合期望的底层映射H(X),现在是拟合相对原来X的残差F(X),即F(X) = H(X) – X
- 过去:直接拟合H(X)
- 现在:拟合残差F(X)
- 在极端的条件下,如果恒等映射可以被优化出来,那么让残差为0(这样理论上久不会更差)
0x02 Deep Residual Leaning
1. Residual Leaning
- 原先是直接拟合函数H(X),现在是拟合残差F(X)
- 本质:传统多层网络难以拟合恒等映射(什么都不做很难)。加了恒等映射后,深层网络至少不会比浅层更差。如果恒等映射已经最优了,残差模块只需拟合零映射
2. Identity Mapping By Shortcut
通过短路连接传递恒等映射

$$F = W_2\sigma(W_1x)$$
表示第一层输出后用激活函数激活,第二层输出后不激活(论文里用的是ReLu函数)
- 为了简化,偏置项biases被省略了(如果卷积层后面加了BN层,那么也不需要偏置项了,因为期望变为0了)
- 通过短路连接把残差和恒等映射逐元素相加,然后再用ReLu激活
- shortcut没有引入额外的参数和计算复杂度(加法基本没有影响),那么就可以很简单地和没有带残差块的网络进行对比
- 残差模块的输出F(x)的尺度要和自身的输入x的尺度保持一样,这样才可以逐元素相加。如果不一样(比如做了下采样),那么shortcut的x要做一下处理和残差块的输出一样:

- 为什么不统一采用WsX,而是在尺度一样的情况下用X?
- 为了不引入多余的参数,减小复杂度,而且很多时候,保持恒等映射效果更好
- 残差分支在本论文为2层,更多层也是可以的。但是如果只有一层,那就相当于线性层了,因为在与自身输入逐元素相加之前没有经过非线性函数的激活
3. Network Architectures
网络架构。这段就是对比带残差的网络和不带残差的网络
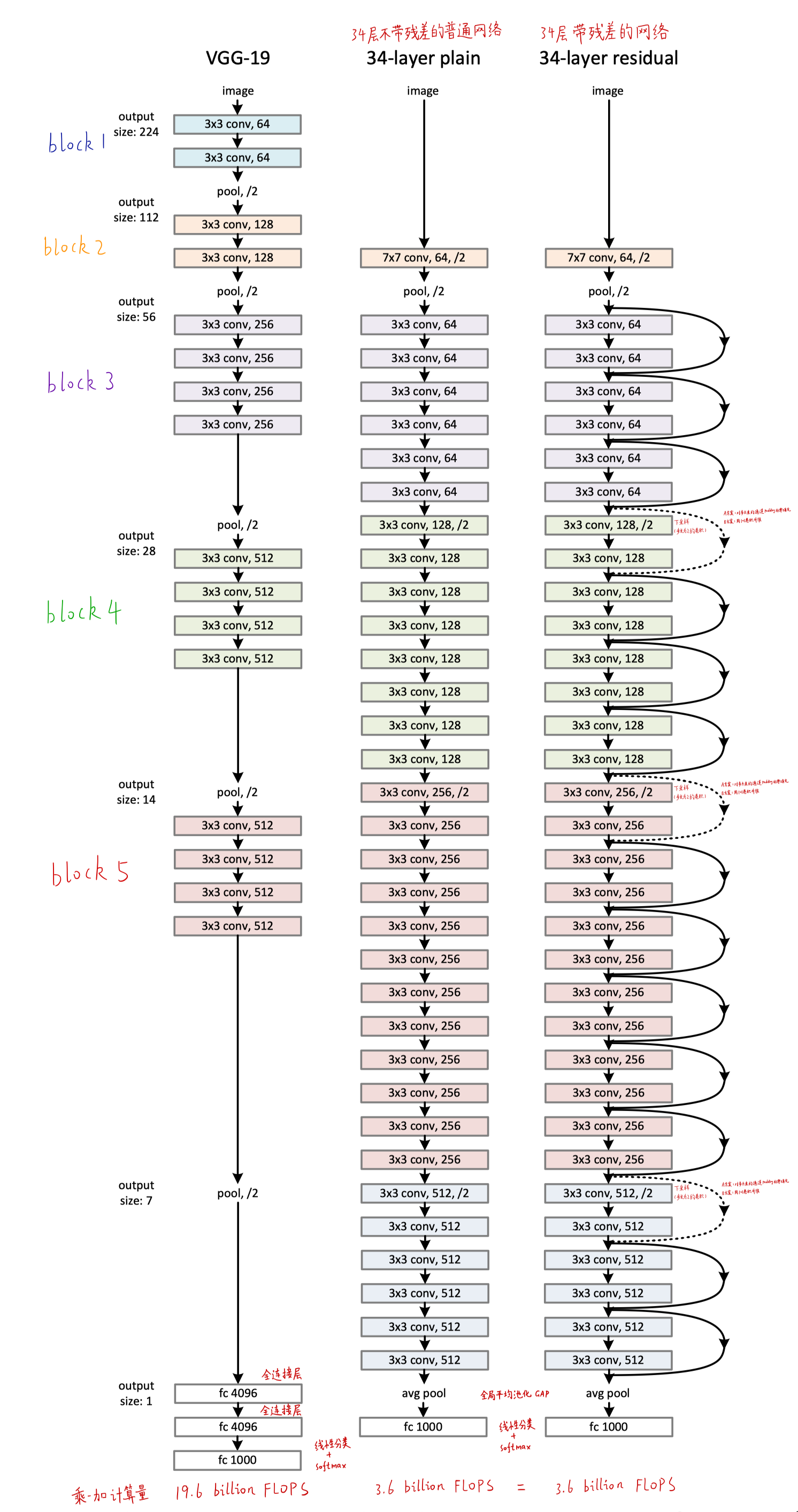
3.1 Plain Network
普通无残差网络
- 类似VGG,所有的卷积核都是3×3
- 每个block内filter个数不变
- feature map大小减半的时候,filter个数x2
- 不同于VGG使用池化进行下采样,这个网络用步长为2的卷积进行下采样
- 不同于VGG使用全连接层,这个网络使用全局平均池化(GAP),这样可以大大减少参数个数和计算量
- 最后得到1000个类别,再用softmax得到归一化的概率
- 这个34层的网络有着比VGG更少的参数
- VGG-19的计算量是19.6b FLOPs,这个网络是3.6b FLOPs,只有它的18%
3.2 Residual Network
带残差的网络
- 基于上面的34层普通网络,加入shortcut连接,就变成了这个网络
- 图中的实线表示维度一样,虚线表示维度x2,匹配维度的方案有:
- A方案:对多出来的通道多padding补零,也就恒等映射的那一路shortcut要加上一倍全为0的通道(没有引入额外的参数)
- B方案:用1×1卷积升维
- 不管采用上面哪种匹配维度的方案,残差分支的第一个卷积层步长都为2(宽高减半,通道翻倍)
4. Implementation
- 图像增强:
- 随机resize到[256, 480]之间,然后用224×224随机裁切
- 水平镜像
- 颜色增强
- 在每个卷积层后面,激活之前都用上BN
- 没用使用dropout,因为不能和BN同时用
0x03 Experiments

1. Plain Network
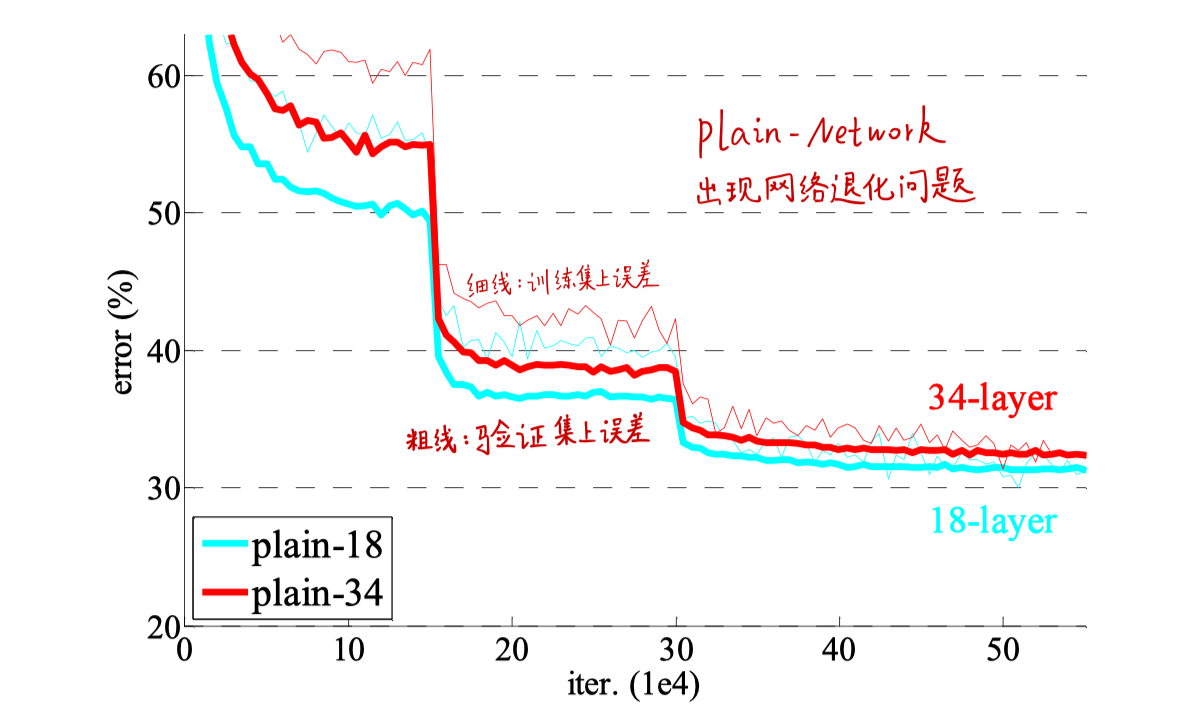
- 更深的34层网络的验证误差要比18层网络的要高
- 34层网络在整个训练过程中都有这更高的误差(网络退化)
- 34层网络有着更大的模型容量和求解空间,但是实际效果却更差
- 网络退化不是由梯度消失导致的,因为BN层确保了前向传播的信号有非零方差(不会全部挤在一个数附近,而是会分散开)
- 做了实验发现前向传播和反向传播都没问题
- 推测是因为网络的深度会指数级地降低收敛速度,这样反而不适合训练(不适合学东西)。但是又做了实验,增加迭代次数,延长训练时间,结果也是一样,34层的还是有更大的误差,可能这个plain network本身就不适合
2. Residual Network
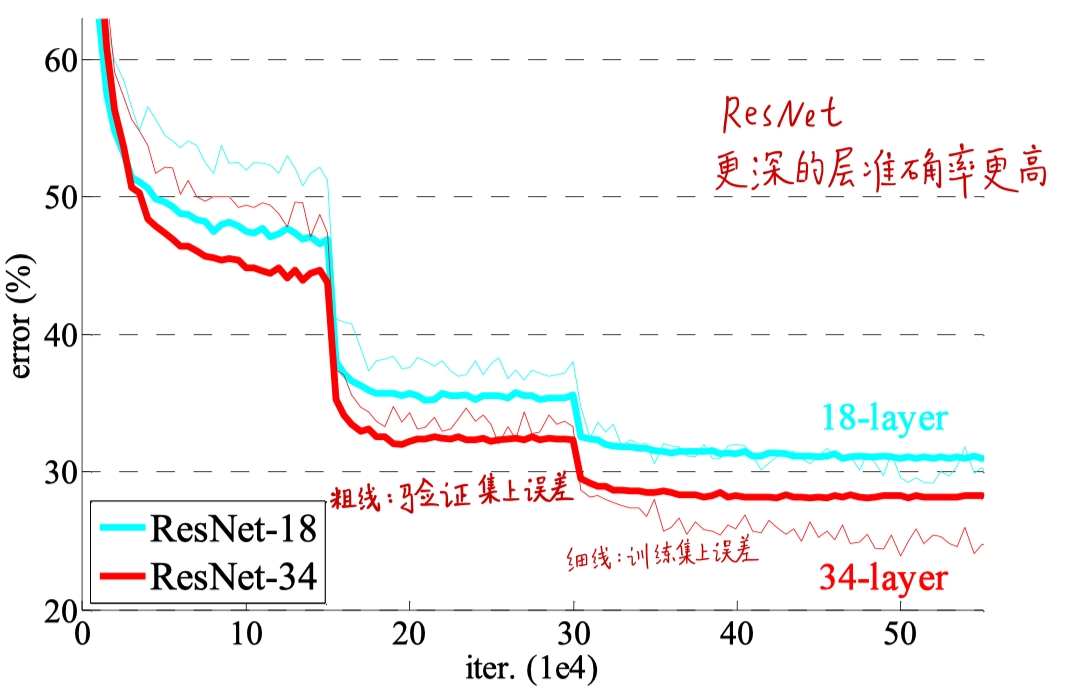
- 除了带残差shortcut,其他都和plain network一样
- 网络退化问题得到解决
- 匹配通道使用了padding补零,因此也没有引入额外参数
- 残差学习可以用于搭建非常深的网络
- 带残差的收敛更快,训练更快(梯度可以通过shortcut connection传到底层,有利于收敛)
3. Identity vs. Projection Shortcuts.
比较使用恒等映射还是其他映射处理
- A方案:所有shortcut无额外参数,升维使用padding补零
- B方案:平常的shortcut用identity mapping,升维时用1×1卷积升维
- C方案:所有的shortcut都使用1×1卷积
结论:

- ABC三个方案都比不带残差的plain network好
- B比A好,A在升维的时候用padding补零,相当于丢失了shortcut分支的信息,没用进行残差学习
- C比B好,C的13个非下采样残差模块的shortcut都有参数,模型表示能力强
- ABC差不太多,说明identity mapping的shortcut足以解决网络退化问题
4. Deeper Bottleneck Architectures
- bottleneck:输入和输出都是高维的,中间是低维的

- 用1×1卷积先降维,再升维
5. 50-layer ResNet
把34层resnet中的只有2层的残差块换成了3层的bottleneck残差块
6. 101-layer and 152-layer ResNets
- 也是用3层bottleneck构建的
- ResNet-152的计算量依然比VGG-19要低








评论 (0)