

0x01 EfficientNet V1
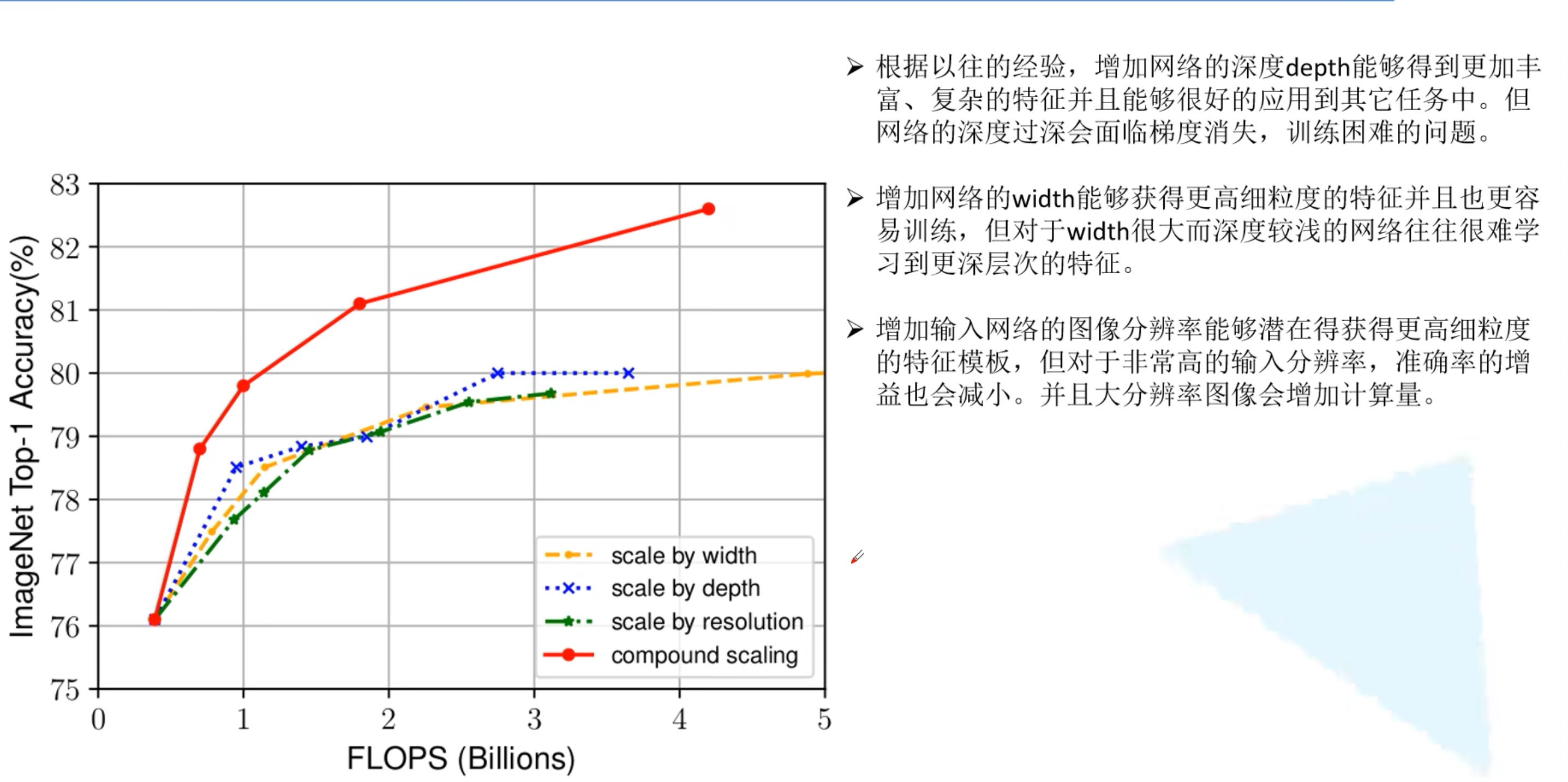
- 同时探索输入分辨率、网络深度、宽度的影响
- 在论文中提到,EfficientNet-B7在ImageNet top-1上达到当年最高准确率84.3%
- 准确率高,参数少,但是占用gpu显存多(因为使用分别率高的图像)
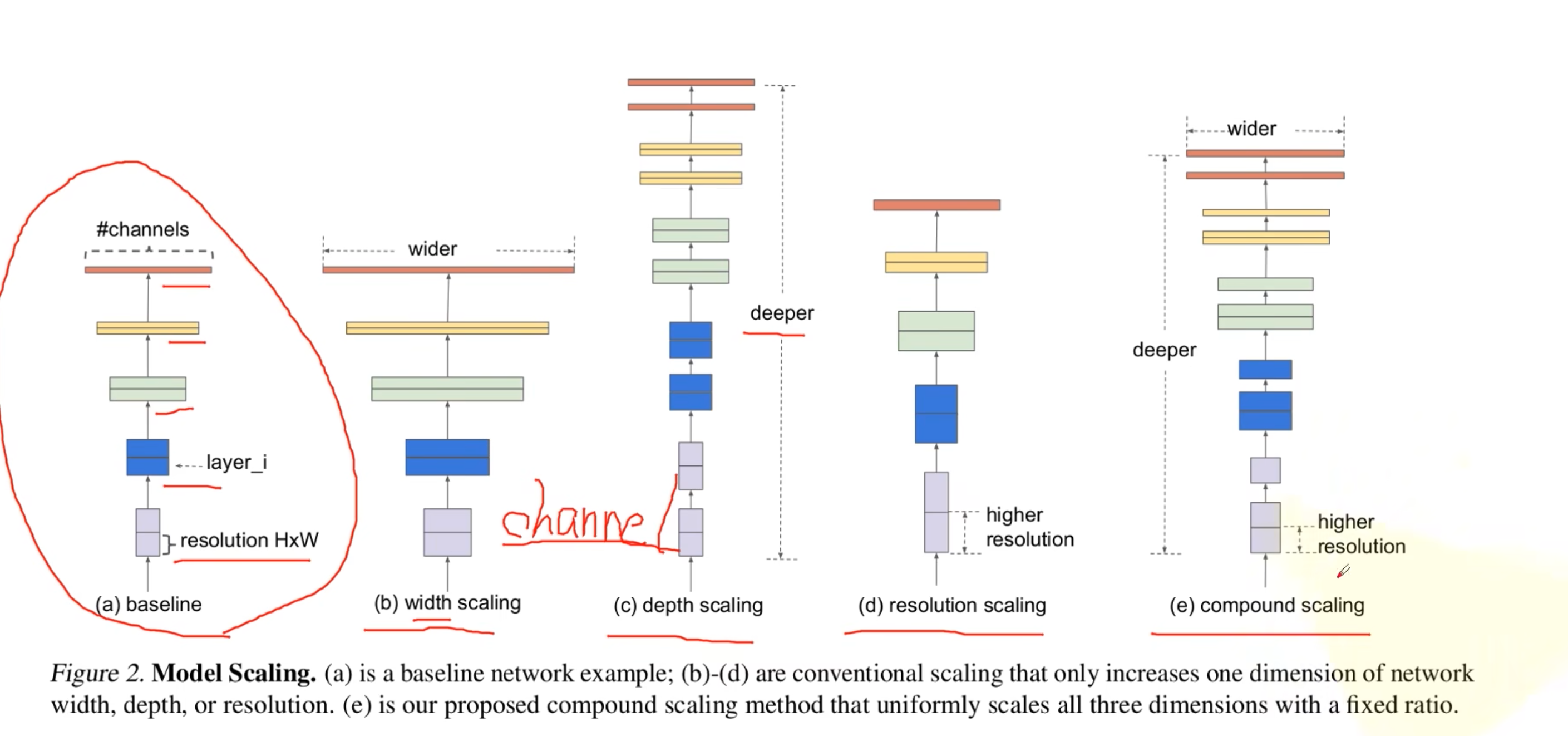
- a:基准网络
- b:提高网络宽度,也就是channel
- c:提高网络深度
- d:提高分辨率
- e:同时提高
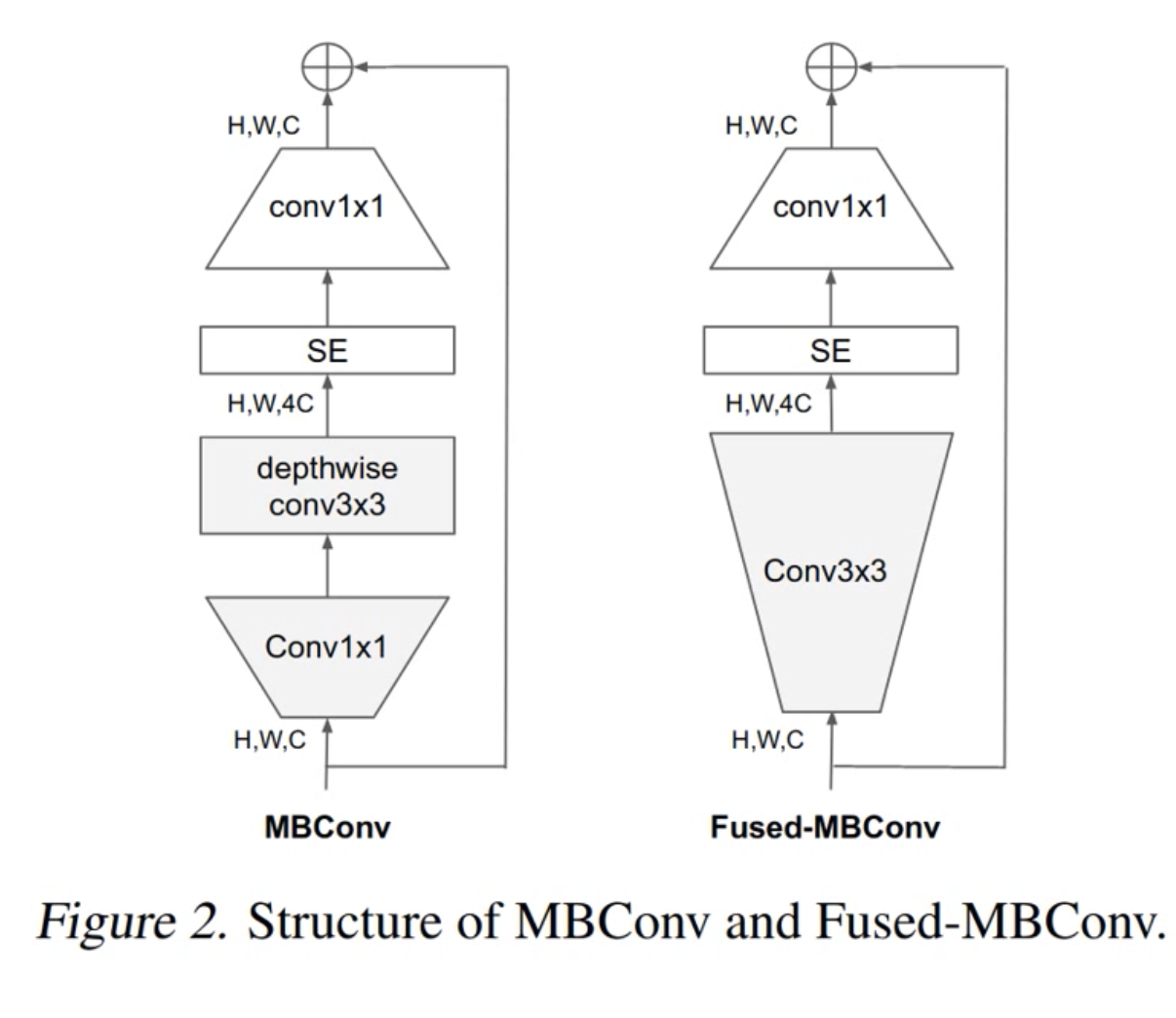
1. MBConv
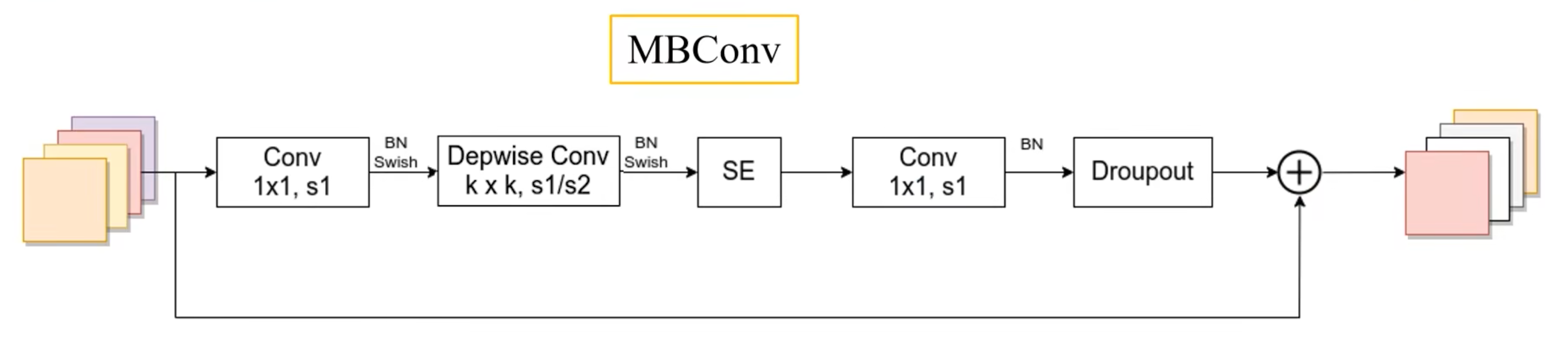
- 与MobileNetV3用的block是一样的
- 第一个升维的1×1卷积,它的卷积核个数是输入特征矩阵channel的n倍
- 当n=1时,不要第一个升维的1×1卷积层
- 关于shortcut连接,仅当输入MBConv结构的特征矩阵与输入的特征尺寸shape相同才存在
2. SE模块
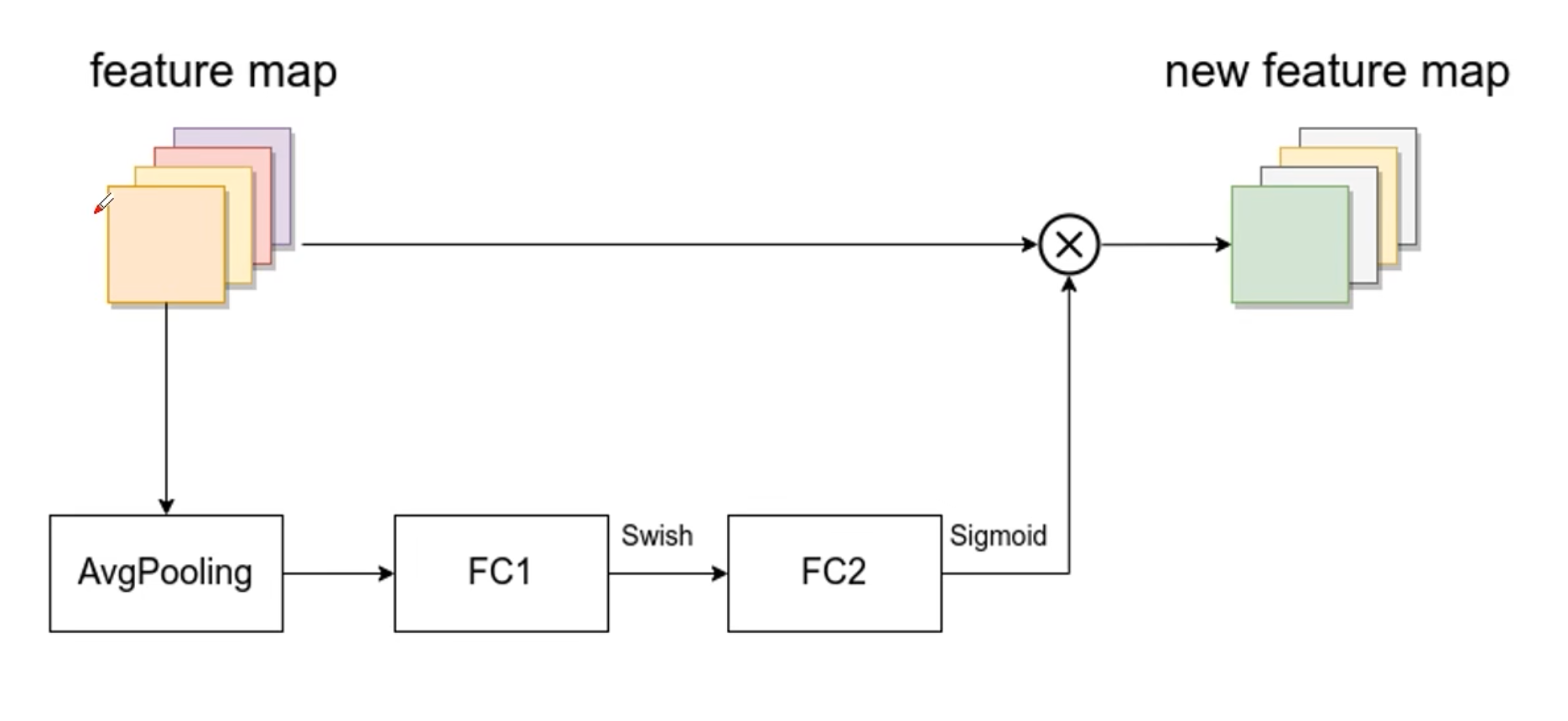
- 由一个全局平均池化,两个全连接层组成
- 做乘法部分,channel要一样
0x01 EfficientNet V2
- V1中作者关注的是准确率以及FLOPs,V2中作者进一步关注模型的训练速度
- V1中存在的问题:
- 训练图像的尺寸很大时,训练速度非常慢
- 在网络浅层中使用DW卷积速度会很慢
- 同等地放大每个stage是次优的
1. Fused-MBConv结构
在网络浅层使用DW速度会很慢。无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快),因此引入了Fused-MBConv结构








评论 (0)