

Fully Convolution Networks全卷积网络
- 首个端对端的针对像素级预测的全卷积网络
- 把分类CNN网络最后的全连接层替换为卷积层
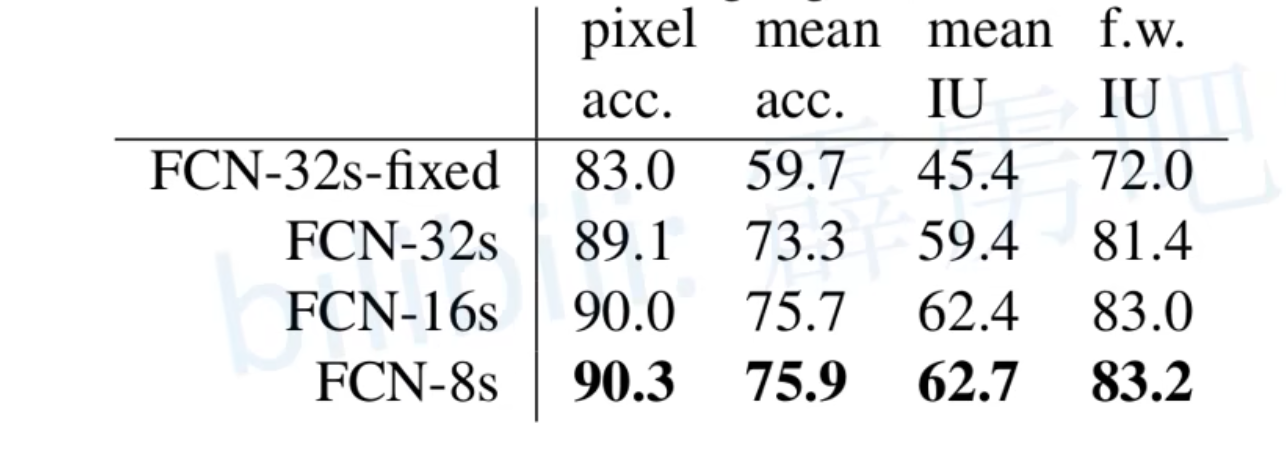
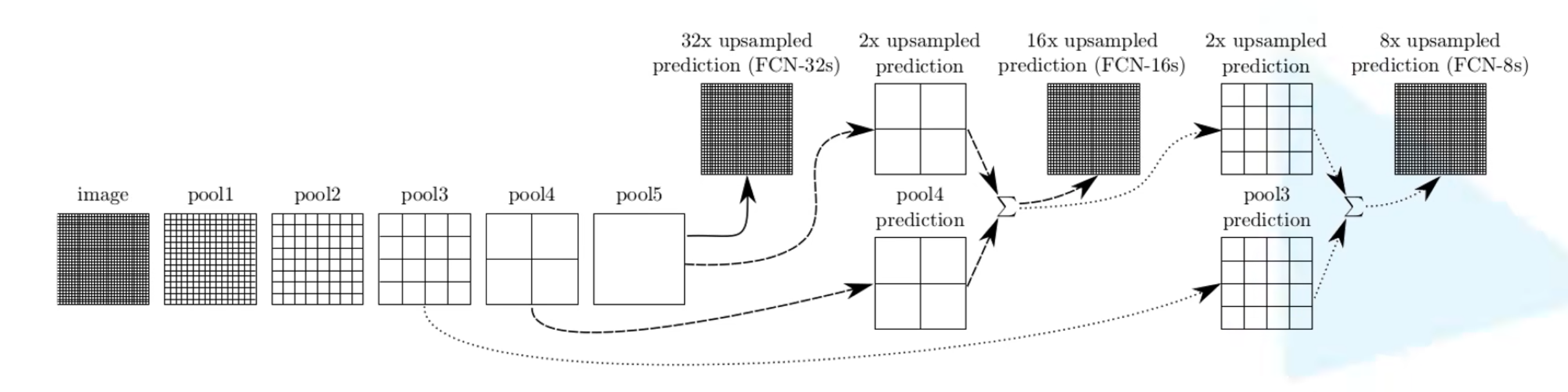
- 有FCN-32s、FCN16s和FCN-8s多个版本
- 通过32倍上采样还原到原图的就是FCN-32s。另外两个类似
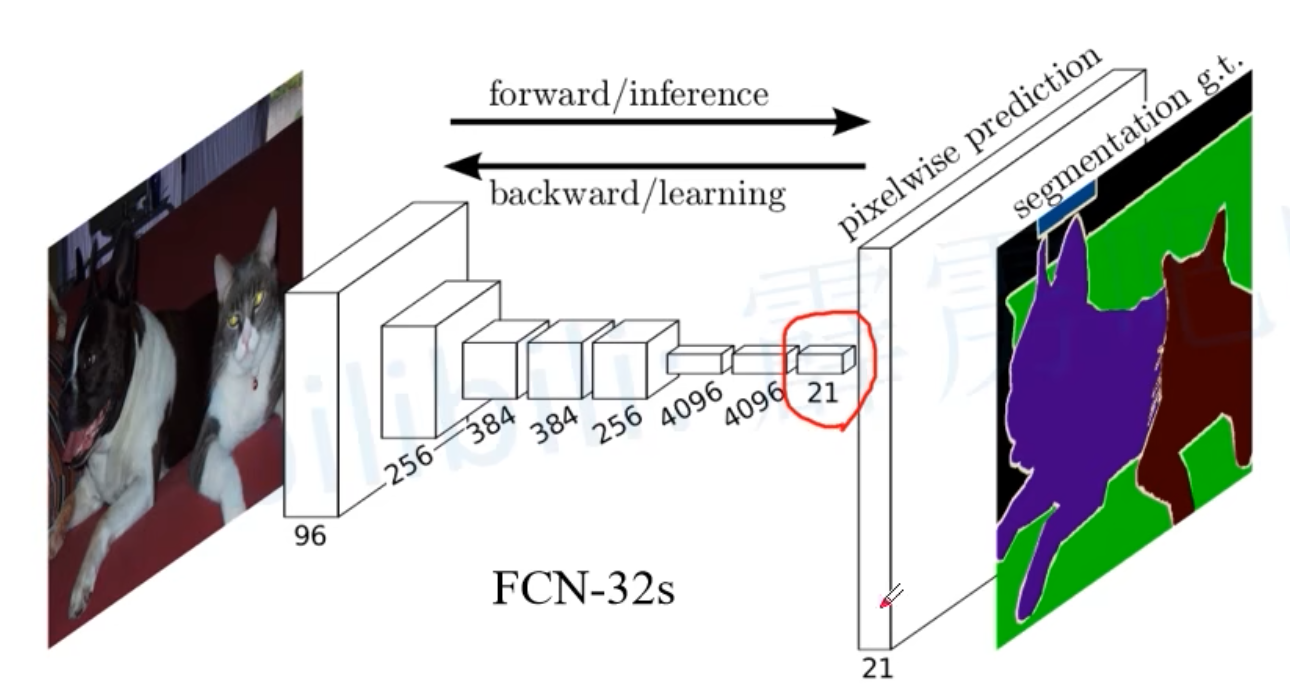
0x00 用VGG-16作为backbone
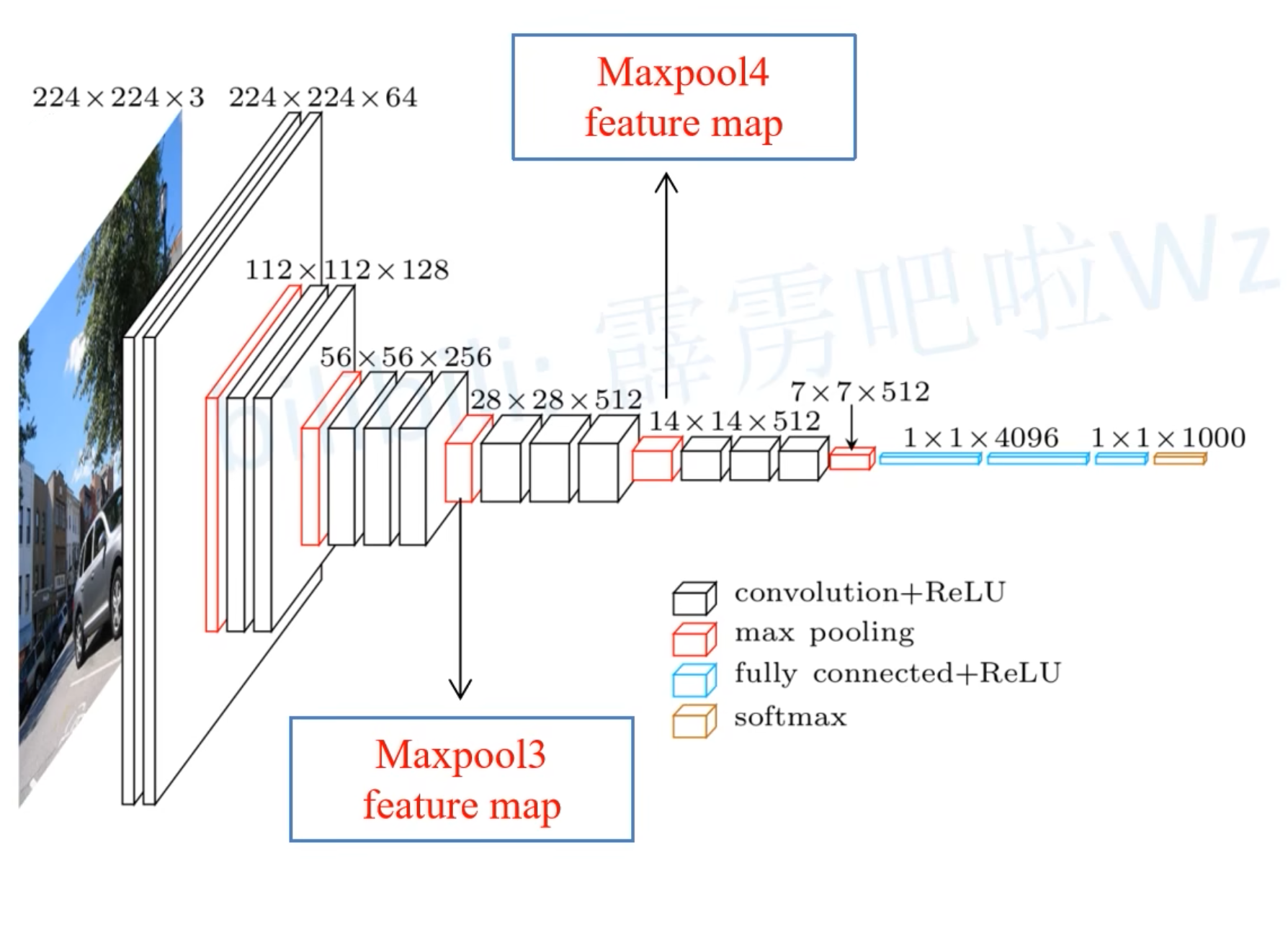
- 在Maxpool3这一层,为8倍下采样。feature map的尺寸为h/8, w/8。h和w为原始输入图像的尺寸
- 在Maxpool4这一层,为16倍下采样.feature map的尺寸为h16,w/16
- 原始的VGG网络最后两层是全连接层,在FCN中,使用卷积层代替,但是修改前后的参数一样:
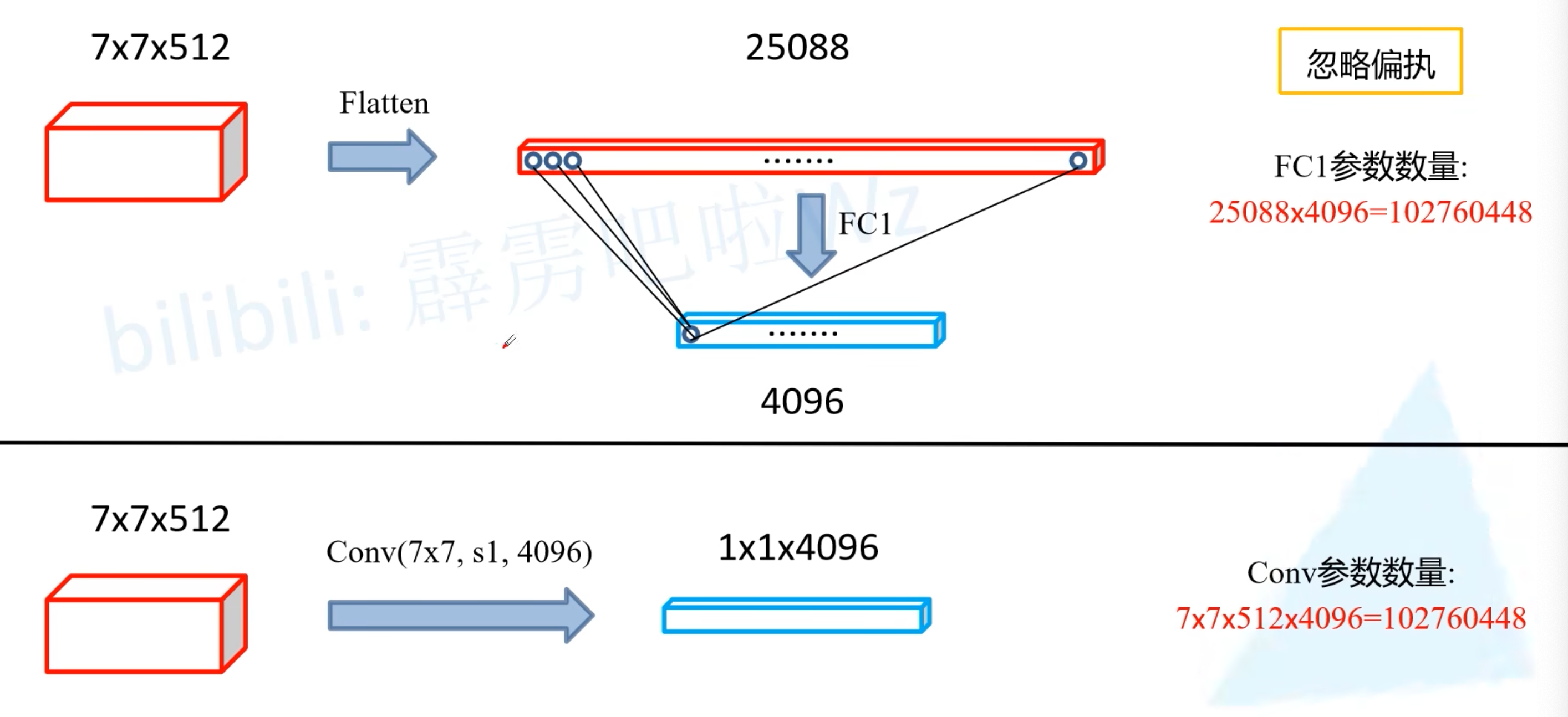
- 使用4096个7x7x512的卷积核代替全连接层(padding=0),也可以得到1x1x4096的feature map(但是要注意原来使用全连接层前经过flatten操作,所以没有保留宽高信息,准确地说是4096个长度的特征向量)
- 因此,就可以直接使用原先VGG网络的全连接层的权重,做reshape处理,就可以将权重改为(4096, 7, 7, 512)给这个卷积层直接使用了
通过32倍上采样还原到原图大小的是FCN=32s。另外两个版本类似
0x01 转置卷积
- 转置卷积不是卷积的逆运算
- 转置卷积也是卷积
- 作用:up sampling
- 卷积不会增大输入的高宽,通常要么不变,要么减半
- 而转置卷积则可以用来增大输入的高宽
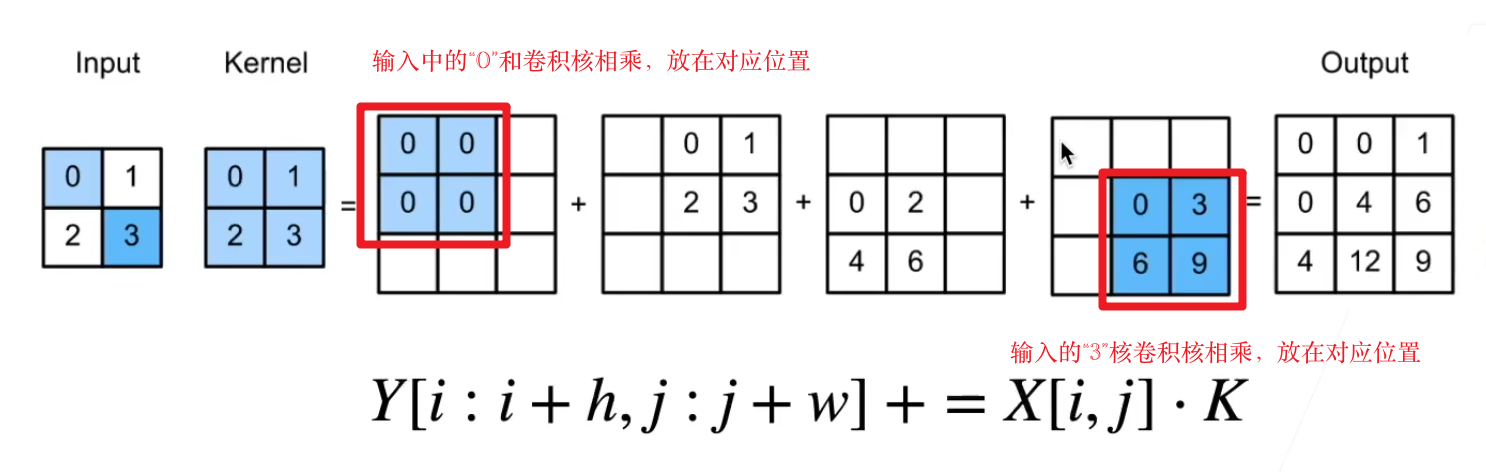
- padding: 填充。但这里和普通卷积相反,可以理解为反填充。
- 正常卷积是:input -> padding -> conv -> output
- 转置卷积是:input -> transconv -> depadding -> output。上图如果做一个padding=1的填充,那么输出就是只有一个4
- stride:步幅。每次算完之后往后面移动多少步,和普通的卷积一样
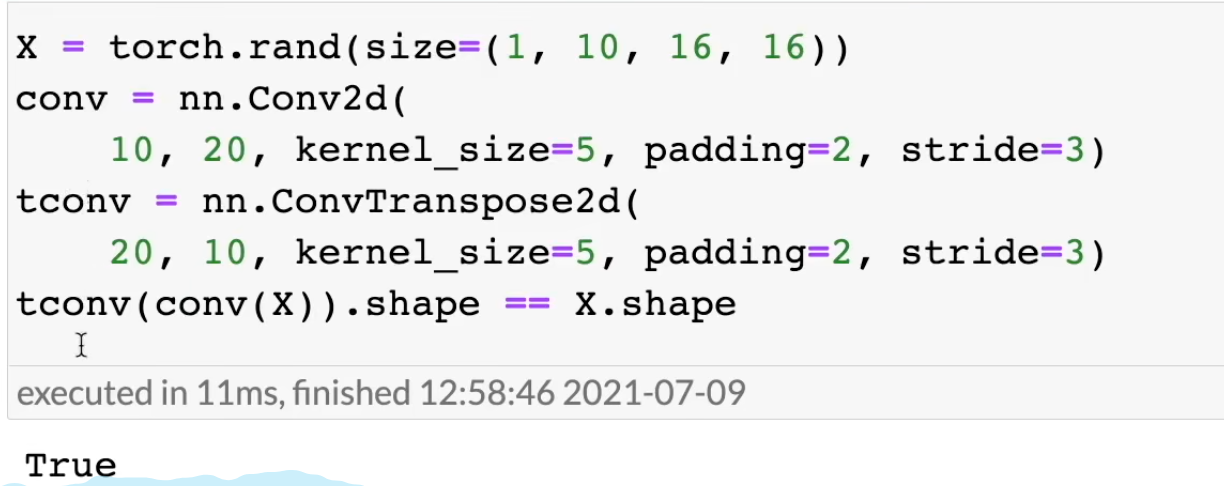
如果输入X经过一个普通卷积Conv再经过一个反卷积ConvTrans,其中这两个卷积的kernel_size、padding、stride都一样,那么输出的尺寸也和输出X的尺寸一样
0x02 FCN-32s
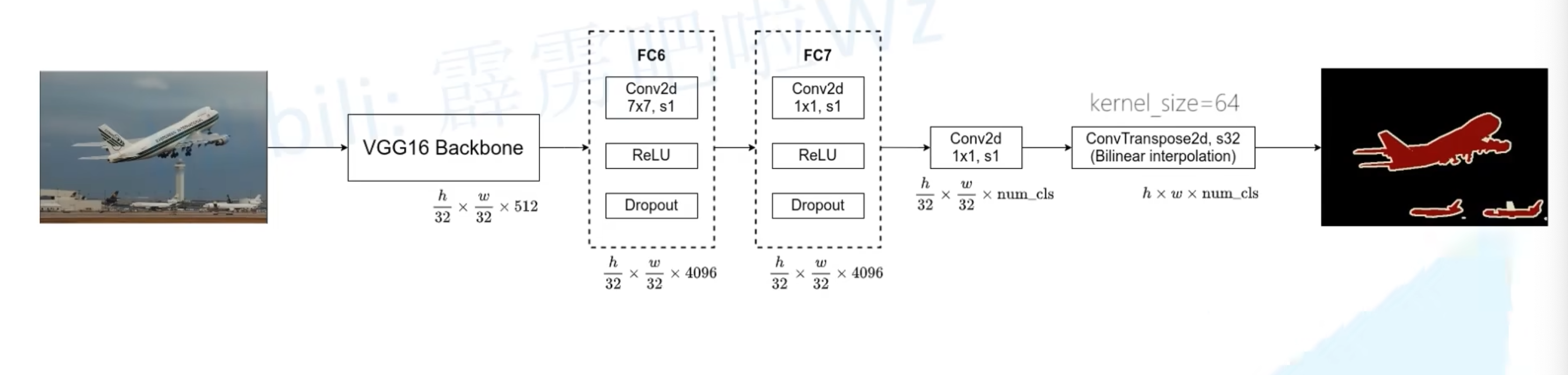
- 原论文在VGG-16的第一个卷积层padding设为100
- 作者给出的解释是为了适应不同大小的输入图片
- 假如padding==0,当输入尺寸为196×196时,经过32倍下采样就变味6x6x512的feature,这样如果要和FC6层的7×7卷积核做卷积操作就会报错
- 举一个更为极端的例子,如果输入图片尺寸小于32×32,如果不做padding,那么还没有经过backbone就会报错了。所以作者就用了padding==100
- 但是实际上我们做项目并不需要加padding,,因为实际的图片分辨率都比较大。所以只要在FC6的那个卷积层把padding设为3,就可以训练任意大于32×32尺寸图像了
- VGG16 backbone就是VGG-16除去最后两个全连接层后的网络,通过backbone之后做了32倍下采样
- FC6层使用7×7的卷积核,通常padding==3,这样经过卷积处理后不会改变featuremap的宽高尺寸
- FC7使用1×1的卷积,因此也不会改变feature map的宽高尺寸
- 通过1×1卷积把维度降到num_cls。(注意是包括背景的)
- 最后使用一个转置卷积进行32倍上采样还原到原图的尺寸,通道数为num_cls,对通道内的数据做softmax处理就可以得到属于哪一个类别了
- 在论文源码中,最后那个转置卷积的参数其实被冻结了,因此其实可以不用转置卷句,改为使用双线性插值来还原到原图
- 作者通过实验发现冻不冻结差异不大,冻结还可以加速训练过程
- 可能是这个转置卷积的上采样率太大了,才导致冻不冻结差异不大
0x03 FCN-16s
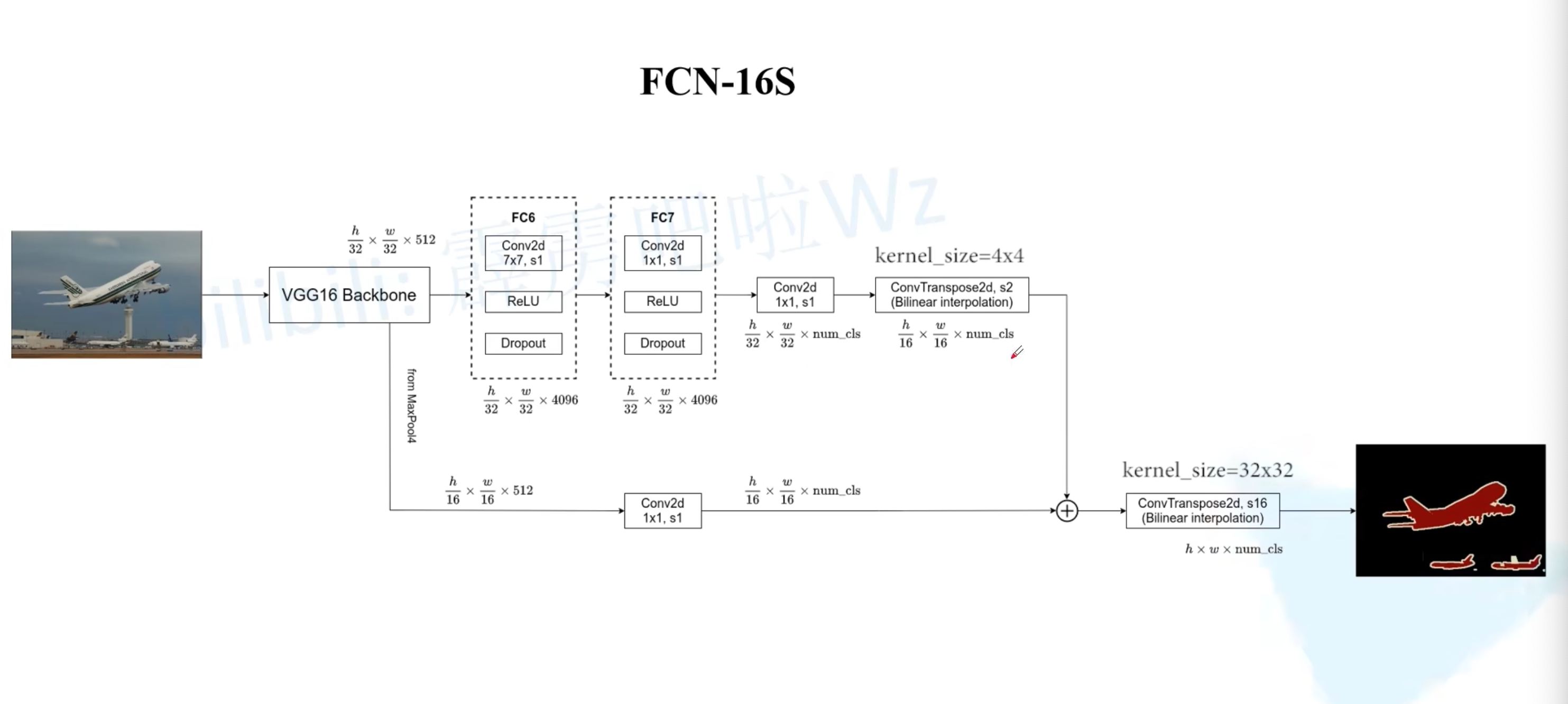
- 相比FCN-32s,多了一路,就是从VGG-16网络中的maxpool4层(这一层对应下采样了16倍)取了出来做1×1卷积后进行相加,再通过一个转置卷积做16倍上采样还原到原图尺寸
- 当然,原来那一路的转置卷积改为上采样2倍,也就是输出的feature map相当于原图做16倍下采样,这样才可以和下面那一路进行相加
0x04 FCN-8s
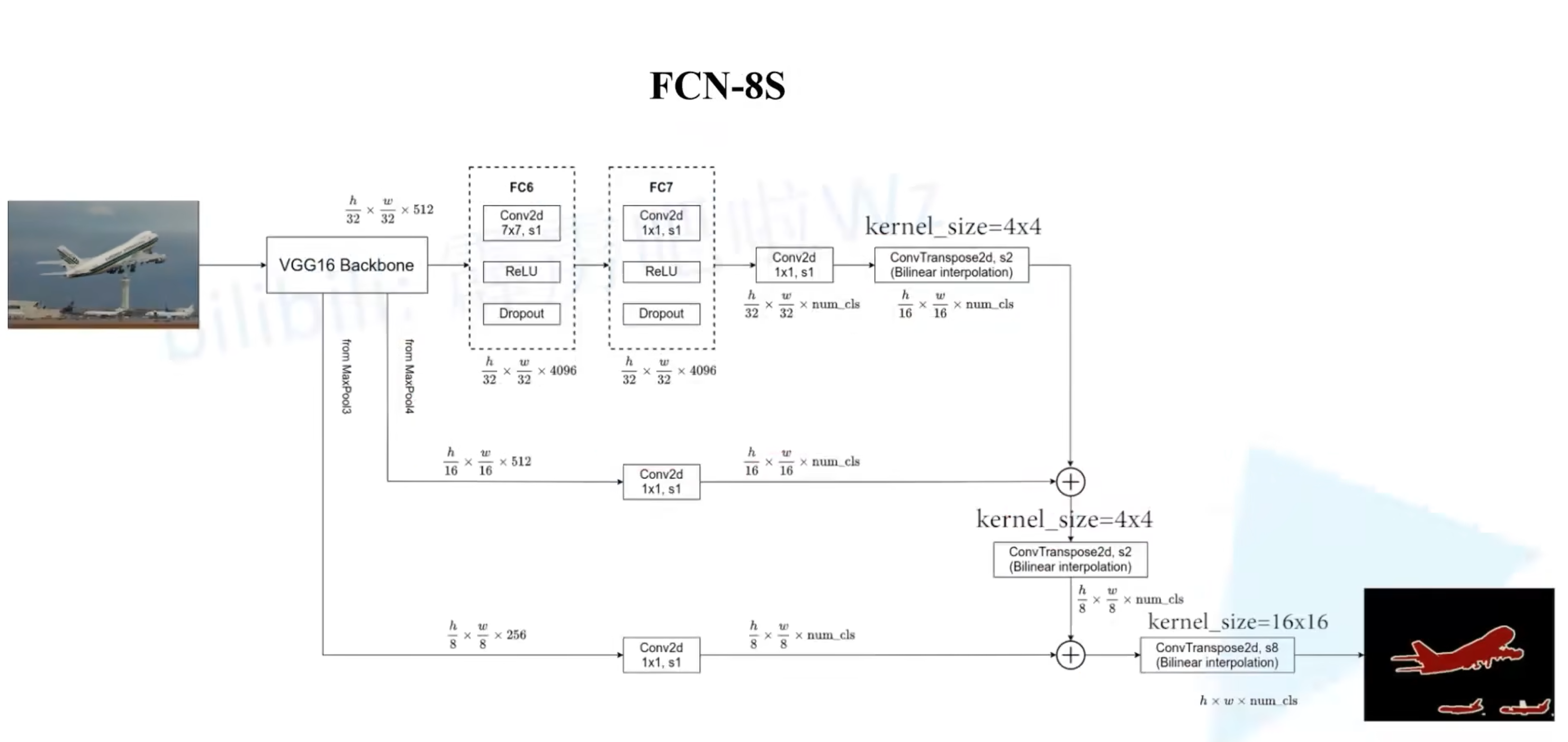
- 和FCN-16s类似,多了一路来之VGG-16的maxpool3层(这一层对应下采样了8倍)
- 所有相加后最后一个转置卷积进行8倍上采样还原成原图尺寸
0x05 损失计算
交叉熵损失Cross Entropy Loss
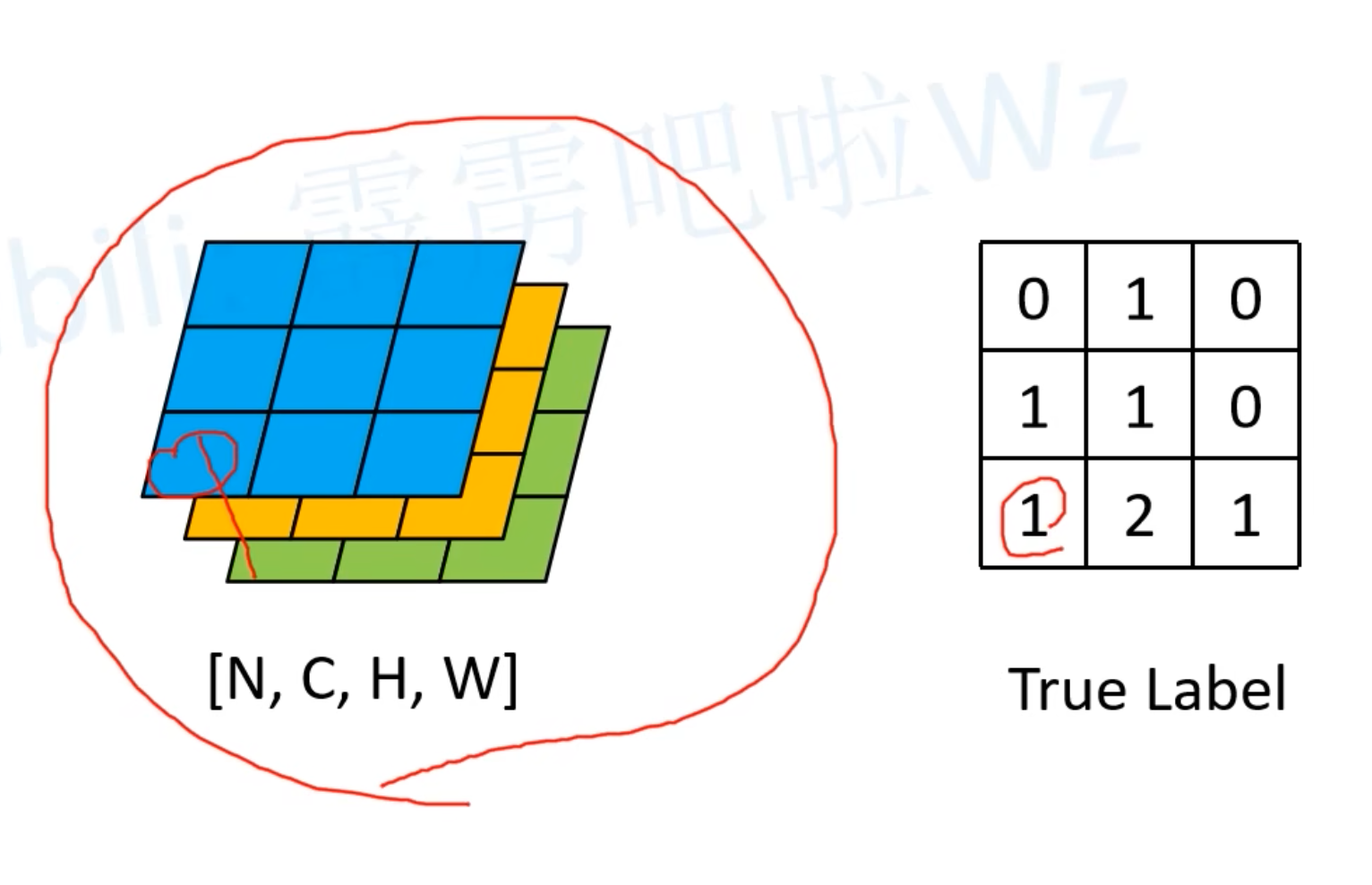
经过Softmax之后可以得到预测的类型,然后每个像素都去与真实标签做交叉熵损失计算,再求均值(共有HxW个)







评论 (0)