

0x01 DeepLabV1
1. 作者提出语义分割存在的问题:
- 下采样导致图像分辨率降低
- 空间不敏感(不变性)
2. 提出的解决方法
- 膨胀卷积
- fully- connected CRF(Conditional Random Filed)——只在V1和V2中使用,V3被淘汰
3. 膨胀卷积(空洞卷积)

- 相比普通的卷积,可以看到卷积核之间是有间隙的,这就是参数r,也就是膨胀因子。如果r=1那就是普通卷积
- 作用:
- 增大感受野(上面的感受野是5×5)
- 保持原输入特征图的W、H(设置合适的padding)
3.1 为什么要使用膨胀卷积?
在语义分割任务中,通常会使用分类网络作为backbone,在backbone中会对图片进行一系列的下采样。通过backbone之后,会使用一系列的上采样恢复原来的图片大小。如果特征图的高宽下采样倍率太大的话,还原到原来尺寸后,图片将丢失很多细节信息。
例如,在VGG网络中,通过max pooling层进行池化,这降低了特征图的高度和宽度,也丢失了一些细节信息,而丢失的信息无法通过上采样进行还原,在语义分割任务中将导致分割的效果不理想。而如果去掉max pooling层,将导致特征图的感受野变小。
而如果直接去除maxpooling,得到的特征图对应原图的感受野就会变小。使用其他下采样方式(如步长为2的卷积)感受野没有才有maxpool的大
3.2 膨胀卷积的缺点——Gridding Effect(网格效应)
网格效应:由于膨胀卷积是一种稀疏的采样方式,当多个膨胀卷积叠加时,有些像素根本没有被利用到,会损失信息的连续性和相关性,进而影响分割、检测等要求较高的任务
如果连续堆叠3个3×3大小,r=2的膨胀卷积,会出现很多像素没有被使用到:

- 数字代表像素被使用到的次数
- 从中间那个像素看,每个像素的感受野都是5×5,但是会有一些没用上的(膨胀卷积,有些没有参与运算)
- Layer1的感受野:1×1
- Layer2的感受野:5×5
- Layer3的感受野:9×9
- Layer4的感受野:13×13
换一种方式:
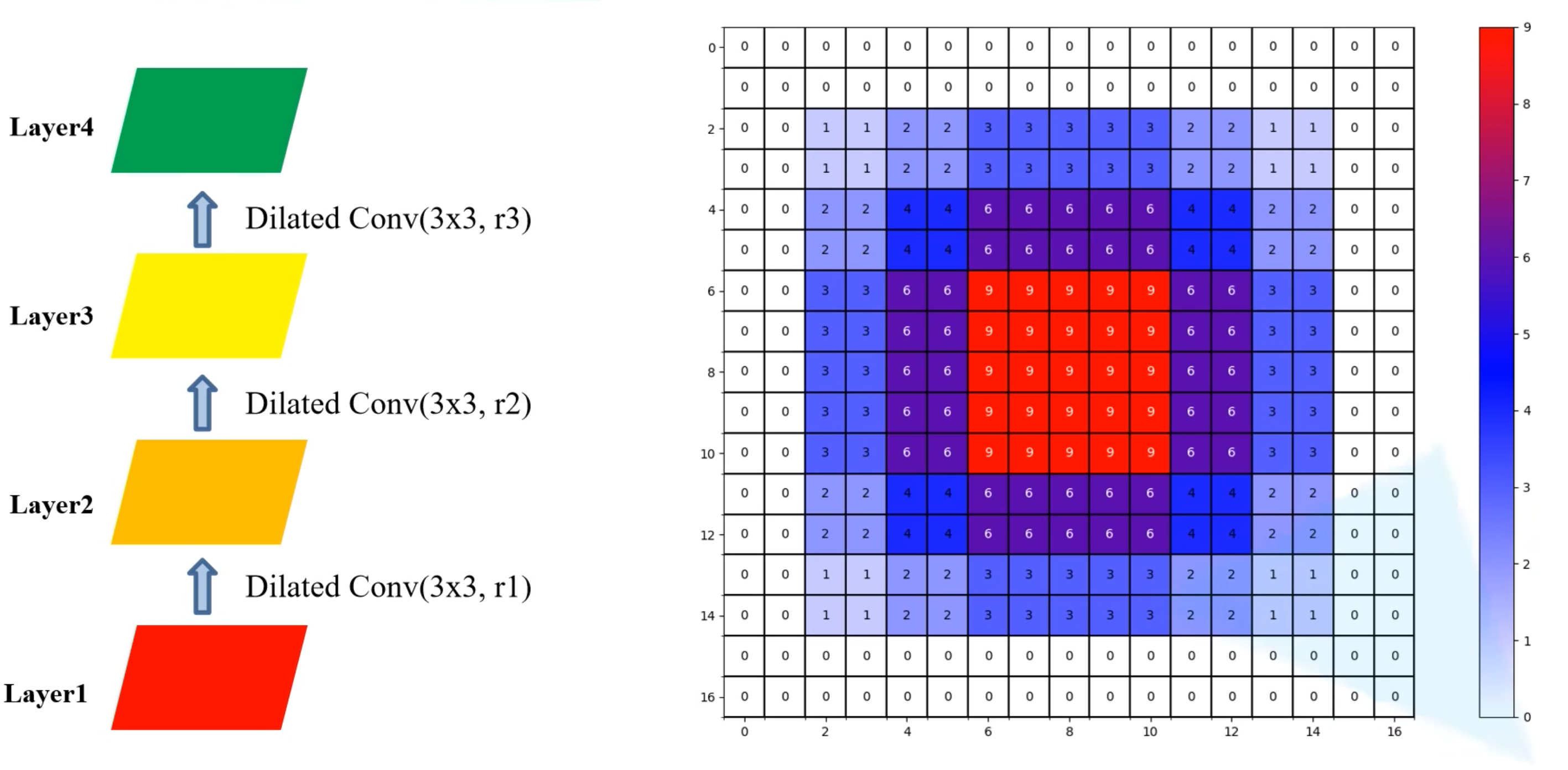
- Layer1的感受野:1×1
- Layer2的感受野:3×3
- Layer3的感受野:7×7
- Layer4的感受野:13×13
- 和之前的感受野一样都是13×13,但是不存在网格效应
再看一组实验,全部使用普通的卷积:
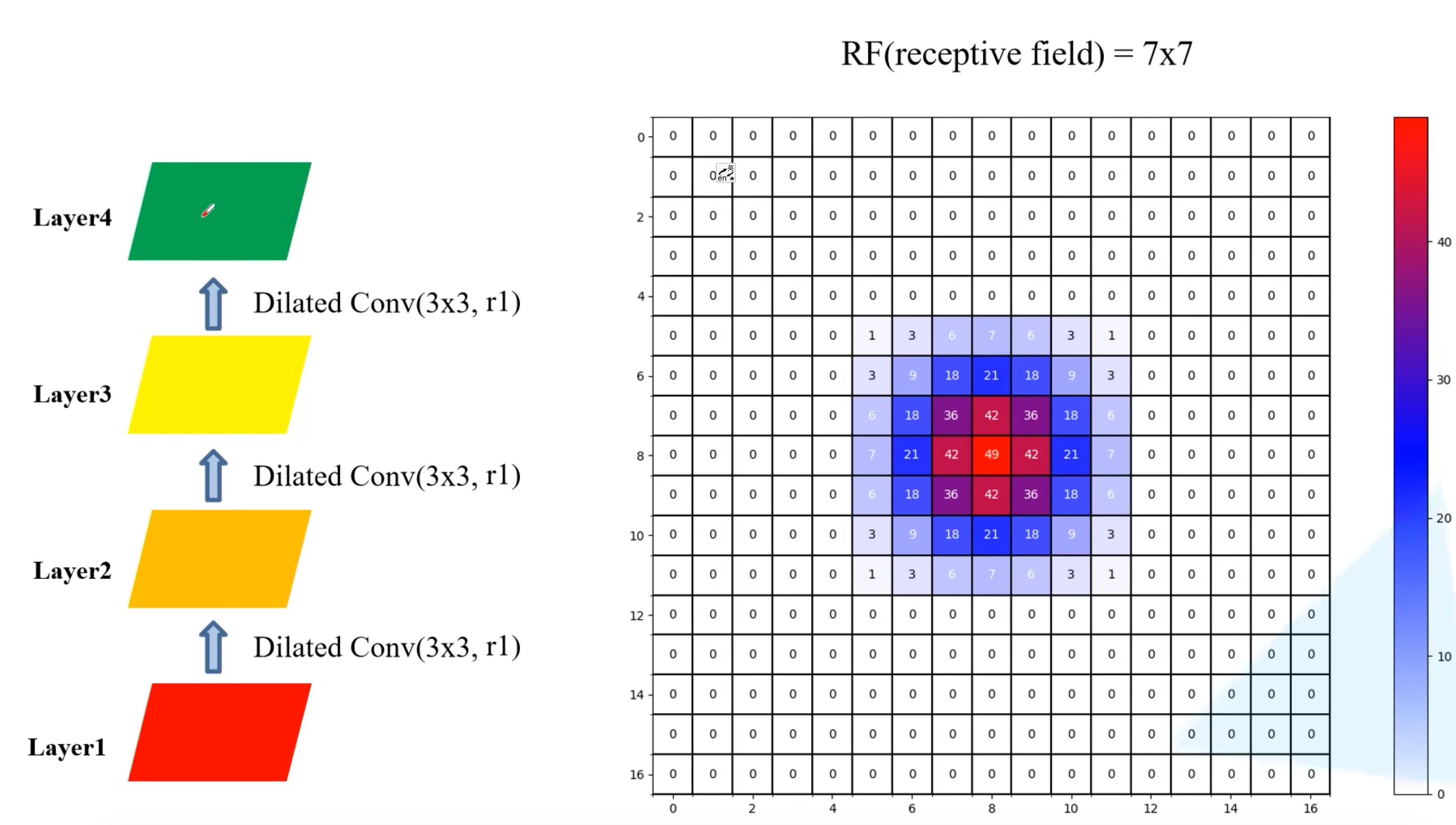
- Layer1的感受野:1×1
- Layer2的感受野:3×3
- Layer3的感受野:5×5
- Layer4的感受野:7×7
- 也是没有存在网格效应,但是感受野没有上一个的大
3.3 如何克服网格效应?
遵循HDC原则
4. 网络优势
- 速度更快,论文中说是因为采用了膨胀卷积的原因,但是fully-connected CRFs很耗时
- 准确率更高,相比之前最好的网络提升了7.2个点
- 模型结构简单,主要由DCNNs和CRFs联级构成(Deep Convolutional Neural Networks)
5. DeepLab-LargeFOV网络结构(Field of View)
- FOV:Field of View
- 本质:采用膨胀卷积来扩大感受野的技术
- 使用效果:在不降低mIOU的前提下,减少模型的参数数量和加快模型训练速度
- backbone:基于VGG-16
- 下采样8倍,不同于VGG下采样32倍
- 对于第一个全连接层(FC1)在FCN网络中是直接转换成卷积核大小7×7,卷积核个数为4096的卷积层,但在DeepLabV1中作者说是对参数进行了下采样最终得到的是卷积核大小3×3,卷积核个数为1024的卷积层(这样不仅可以减少参数还可以减少计算量),对于第二个全连接层(FC2)卷积核个数也由4096采样成1024。

6. DeepLab-MSc-Large-FOV网络结构
- 主干网络和上面的DeepLab-Large-FOV一样
- 融合了原图和前四个maxpool层的信息

0x01 DeepLabV2
1. DCNNs在语义分割中的问题
- 分辨率降低(主要是由于下采样stride>1造成的)——V1提过
- 目标的多尺度问题(同类目标在图像上有不同的尺度,有的是大目标,有的是小目标)——新提出的
- DCNNs的不变性(invariance)会降低定位精度——V1提过
2. 对应的解决方法
- 针对分辨率被降低的问题:一般就是将最后几个Maxpooling层的stride设置为1(如果是通过卷积下采样的,比如ResNet,同样将stride设置为1即可),配合使用膨胀卷积
- 针对目标多尺度问题:最容易想到的就是将图像缩放到不同的尺度分别通过网络进行推理,最后将多个结果进行融合即可。这样做虽然有用但是计算量太大了。为了解决这个问题,DeepLabV2提出了ASPP模块(atrous spatial pyramid pooling)
- 针对DCNNs不变性导致的定位精度降低问题:和DeepLabV1差不多还是通过CRFs解决的,不过这里用的是fully connected pairwise CRF,相比V1的fully connected CRF要更高效点——V3被淘汰
3. 网络优势
- 速度更快
- 准确率更高(当时的State of Art)
- 模型结构简单,还是DCNNs和CRFs联级
4. ASPP结构
- ASPP:atrous spatial pyramid pooling,空洞空间金字塔池化
- 对输入的feature map,分为4条并联分支,分别用不同膨胀率的膨胀卷积进行处理
- 因为使用了不同系数的膨胀卷积,因此感受野也是不一样的,这样就可以处理多尺度的目标检测
- 有padding的,各分支输入前后的feature map宽高尺寸一样的

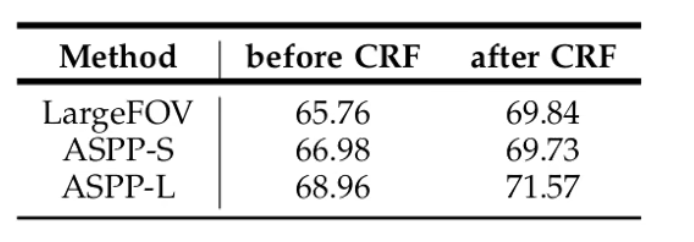
有2个版本ASPP-S、ASPP-L
- ASPP-S:膨胀率:{2,4,8,12}
- ASPP-L:膨胀率:{6,12,18,24}
5. DeepLabV2网络结构
backbone:基于ResNet-101

0x02 DeepLabV3
1. 改进
- 引入了Multi-grid
- 改进ASPP结构
- 移除CRFs后处理
2. 列举了几种获取多尺度上下文信息的网络架构
2.1 Image Pyramid
图像金字塔,将图像缩放为不同的尺度,然后进行正向推理,然后将输出做融合得到最终的输出

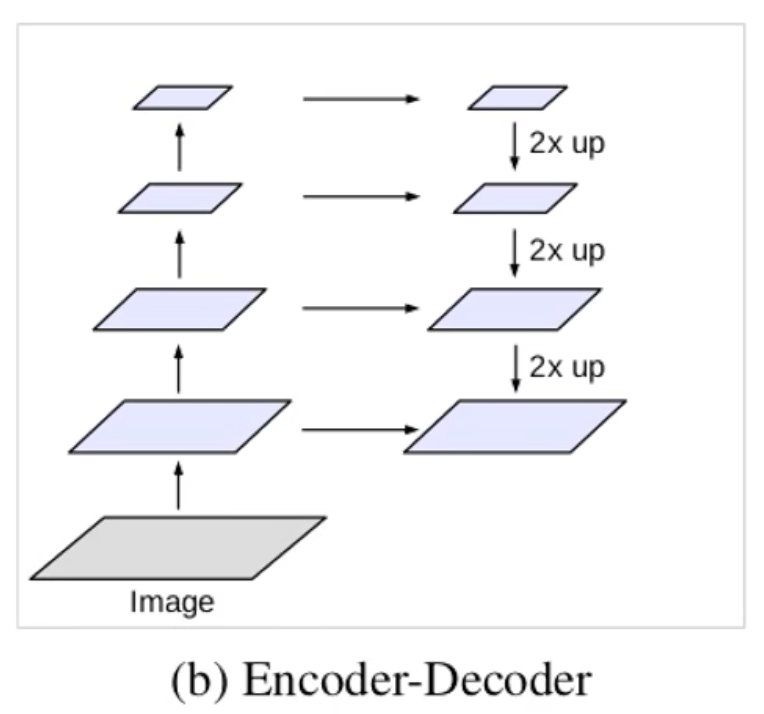
2.2 Encoder- Decoder结构
先将图像做一系列的下采样,然后将最终的特征层做上采样并与对应的浅层特征层进行融合
2.3 将分类网络最后几个下采样层的步长设为1,然后再引入膨胀卷积增大感受野

2.4 ASPP

3. DeepLabV3的两种模型结构
3.1 cascaded(级联) model

Block1,Block2,Block3,Block4是原始ResNet网络中的层结构,但在Block4中将第一个残差结构里的3×3卷积层以及捷径分支上的1×1卷积层步距stride由2改成了1(即不再进行下采样),并且所有残差结构里3×3的普通卷积层都换成了膨胀卷积层。Block5,Block6和Block7是额外新增的层结构,他们的结构和Block4是一模一样的,即由三个残差结构构成。- 原论文中V3在训练时是做了16倍下采样,在验证推理时是做8倍下采样。也就是在Block3处训练时会做下采样,验证不做。
- 作者的解释是:
- 训练时做16倍下采样可以节约显存,增大batch-size,加速训练
- 验证时用8倍下采样效果更好
- 现在显存够用了已经不需要这样做了,训练和验证都用8倍下采样就可以
- 作者的解释是:
- 图中膨胀卷积的系数rate并不是最终使用到的系数,而是要乘以一个参数
multi-grid。比如Block4中rate=2,Multi-Grid=(1, 2, 4)那么真正采用的膨胀系数是2 x (1, 2, 4)=(2, 4, 8)
3.2 ASPP model(效果略好点)

- 一样时训练时16倍下采样,验证时8倍
- 改进了ASPP结构:
- 5个分支:
- 一个1×1的普通卷积层
- 3个膨胀卷积层,系数分别为{6,12,18}(使用16倍下采样)或{12,24,36}(使用8倍下采样要翻倍)
- 1个全局平均池化层(为了获取全局的信息)
- 使用了BN和ReLU
- 融合方式:先concat拼接,再用1×1卷积
- 5个分支:

4. Multi-grid
通过一些实验去设置网络中的膨胀卷积系数设置多少比较合理
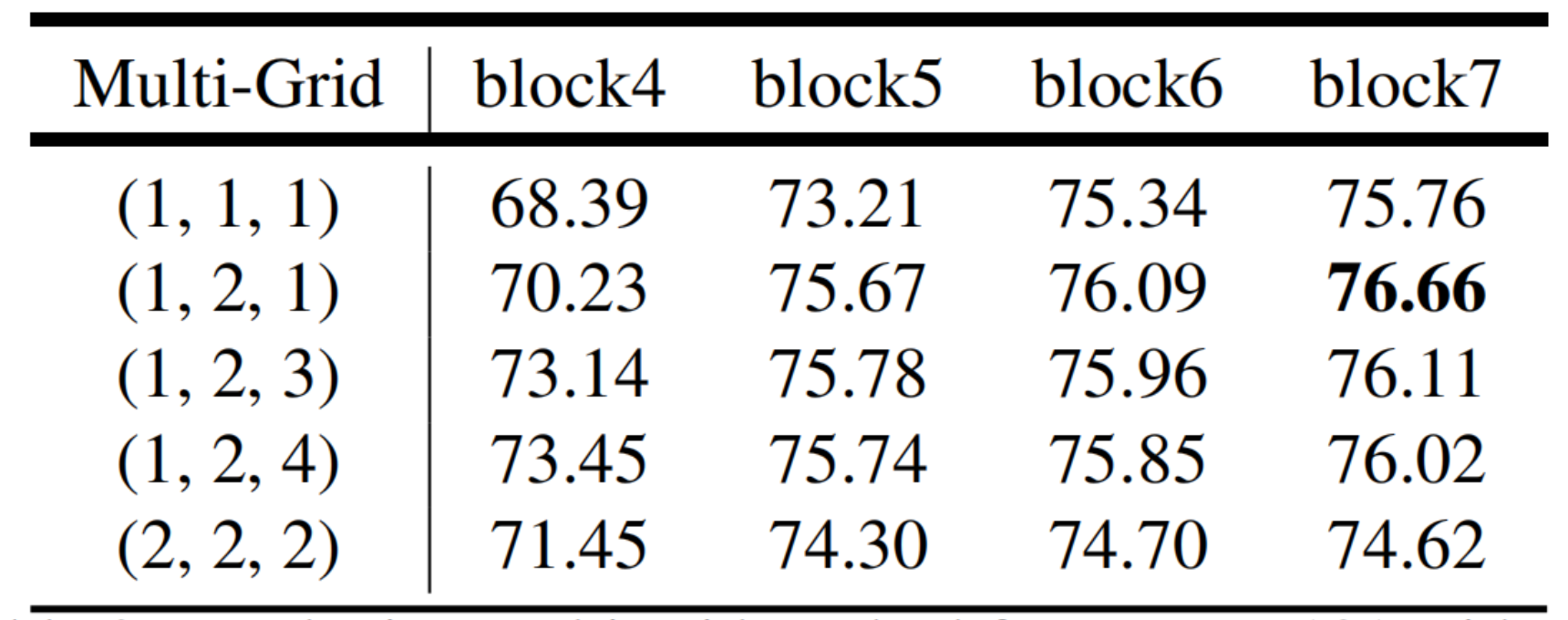
- cascaded model有block5、6、7,ASPP model只有block4
- cascaded model用Multi-grid=(1,2,1)效果最好
- ASPP model用Multi-grid=(1,2,4)效果最好
比如Block4中rate=2,Multi-Grid=(1, 2, 4)那么真正采用的膨胀系数是2 x (1, 2, 4)=(2, 4, 8)(3个膨胀系数时因为每个Block中都由3个残差结构组成)
5. 消融实验
5.1 cascaded model

- MG:Multi-grid
- OS:output_stride:下采样用16倍还是8倍
- MS:multi- scale input:将输入进行多尺度变化再喂入模型训练
- Flip:属于数据增强了,输入图片做水平翻转再喂入模型训练
5.2 ASPP

Image Pooling就是改进后的ASPP中的一个分支
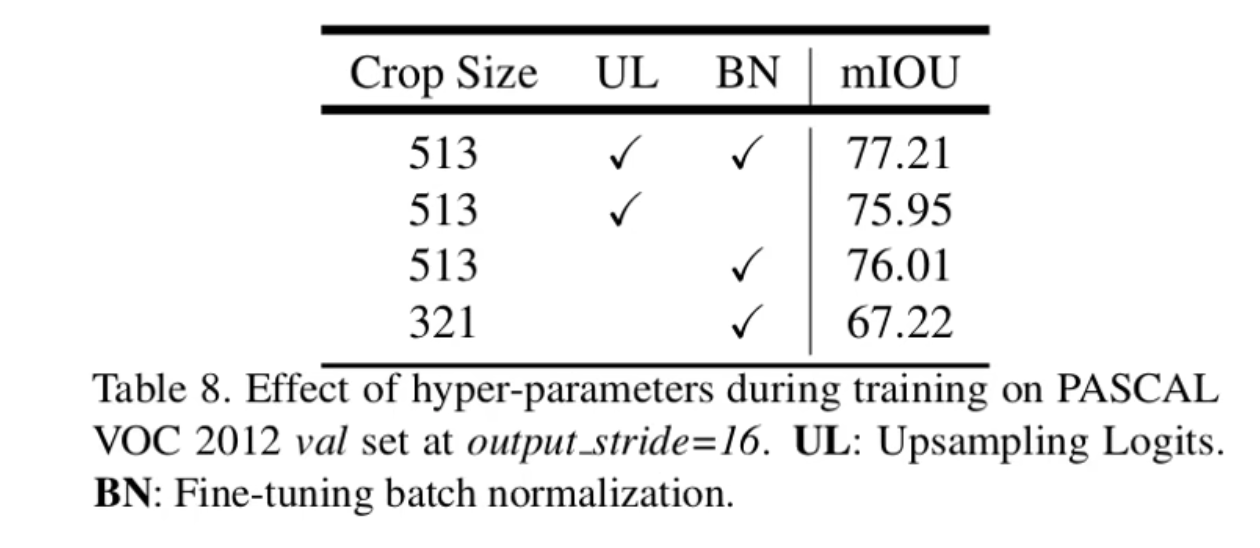
6. 训练细节
- 训练时更大的输入尺寸
- 做上采样还原为原图尺寸之后再计算损失
- V1、V2中是把上采样前计算处理的特征图与真实标签进行下采样后的进行损失计算(为了减少显存、加速训练)
- 训练完成后冻结BN层再去微调其他参数








评论 (0)