

本系列代码托管于:https://github.com/chintsan-code/machine-learning-tutorials
本篇使用的项目为:tree_create
前面我们已经学习了如何计算信息期望、划分数据集、选择最佳的数据集划分方式,本篇将再进一步,通过结合之前的这些功能,构建一个决策树。
目前我们已经学习了从数据集构造决策树算法所需要的子功能模块,其工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于 两个分支的数据集划分。第一次划分之后,数据将被向下传递到树分支的下一个节点,在这个节 点上,我们可以再次划分数据。因此我们可以采用递归的原则处理数据集。
递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。如果所有实例具有相同的分类,则得到一个叶子节点或者终止块。任何到达叶子节点的数据必然属于叶子节点的分类, 如下图所示:
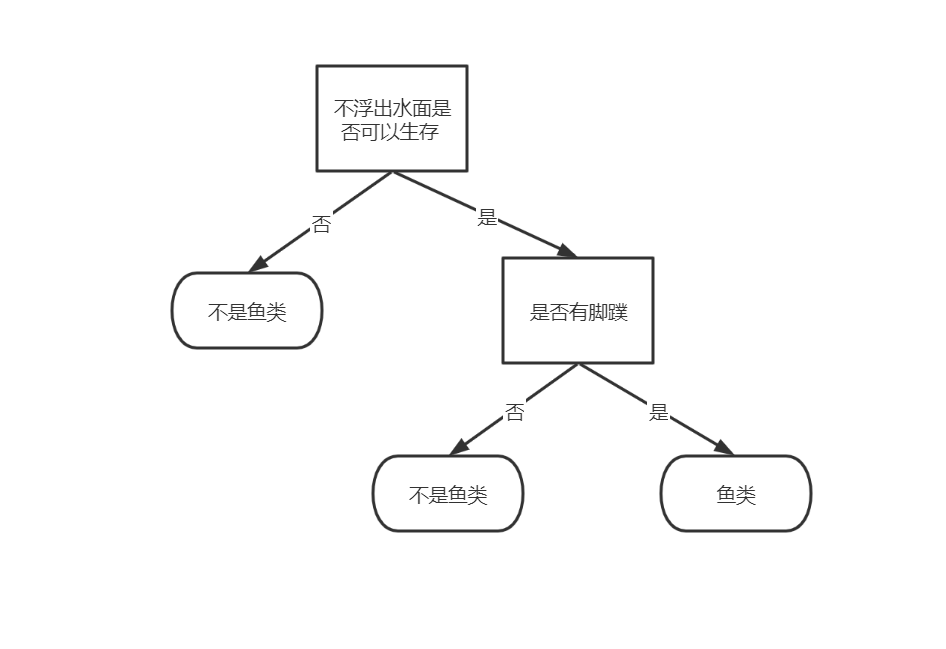
代码如下:
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet] # 获取数据集中的所有类型(标签)
if classList.count(classList[0]) == len(classList): # 类别完全相同则停止继续划分
return classList[0] # stop splitting when all of the classes are equal
if len(dataSet[0]) == 1: # 如果遍历完所有特征,但是类标签依然不是唯一的,返回出现次数最多的
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
del (labels[bestFeat]) # 去除已经在树中的特征标签
featValues = [example[bestFeat] for example in dataSet] # 得到列表包含的所有属性值
uniqueVals = set(featValues) # 找此标签对就的不重复特征值
for value in uniqueVals:
subLabels = labels[:] # copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree这里最关键的就是递归的终止条件:第一个停止条件是所有的类标签完全相同,则直接返回该类标签 。第二个停止条件是使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组(显然,在我们本次的海洋生物数据集中并不存在这种情况)。由于第二个条件无法简单地返回唯一的类标签,这里使用程序清单的函数挑选出现次数最多的类别作为返回值。








评论 (0)