

本系列代码托管于:https://github.com/chintsan-code/machine-learning-tutorials
本篇使用的项目为:regression_lwlr
线性回归的一个问题是有可能出现欠拟合现象,因为它求的是具有最小均方误差的无偏估计。(欠拟合是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。)所以有些方法允许在估计中引入一些偏差,从而降低预测的均方误差。
其中的一个方法是局部加权线性回归(Locally Weighted Linear Regression,LWLR)。在该算法中,我们给待预测点附近的每个点赋予一定的权重;然后与普通最小二乘法一样,在这个子集上基于最小均方差来进行普通的线性回归。与kNN一样,这种算法每次预测均需要事先选取出对应的数据子集。该算法解出回归系数\(w\)的形式如下:
$$
\hat{w}=(X^TWX)^{-1}X^TWy
$$
其中\(W\)是一个矩阵,用来给每个数据点赋予权重(要注意区分这里的权重\(W\)和回归系数\(w\);与kNN一样,该加权模型认为样本点距离越近,越可能符合同一个 )
LWLR使用“核”(与支持向量机中的核类似)来对附近的点赋予更高的权重\(W\)。核的类型可以自由选择,最常用的核就是高斯核,高斯核对应的权重如下:
$$
w(i,i)=exp(\frac{\left | x^{(i)}-x \right |}{-2k^2})
$$
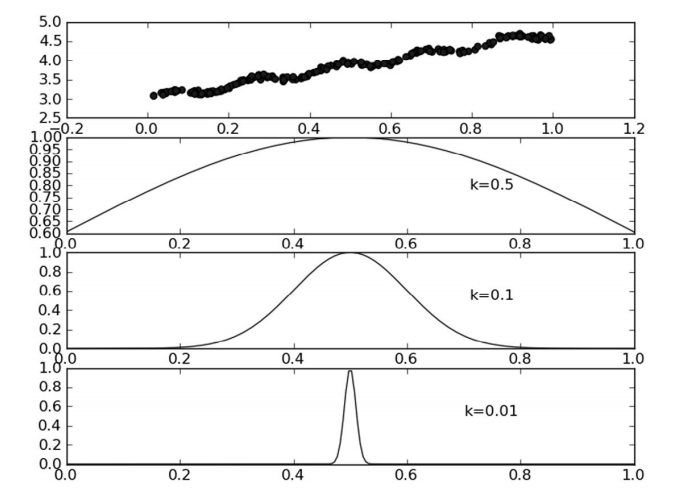
这样就构建了一个对角矩阵\(W\),并且点\(x\)与\(x^{(i)}\)越接近,\(w(i,i)\)将越大。上述公式包含一个需要用户指定的参数\(k\),它决定了对附近的点赋予多大的权重,这也是使用LWLR时唯一需要考虑的参数,在下图可以看到参数\(k\)与权重的关系。
def lwlr(testPoint, xArr, yArr, k=1.0): # 计算testPoint预测值
xMat = mat(xArr)
yMat = mat(yArr).T
m = shape(xMat)[0]
weights = mat(eye((m))) # 创建对角矩阵
for j in range(m): # next 2 lines create weights matrix
diffMat = testPoint - xMat[j, :] #
weights[j, j] = exp(diffMat * diffMat.T / (-2.0 * k ** 2)) # 权重值大小以指数级衰减
xTx = xMat.T * (weights * xMat)
if linalg.det(xTx) == 0.0:
print("This matrix is singular, cannot do inverse")
return
ws = xTx.I * (xMat.T * (weights * yMat))
return testPoint * ws
def lwlrTest(testArr, xArr, yArr, k=1.0): # loops over all the data points and applies lwlr to each one
m = shape(testArr)[0]
yHat = zeros(m)
for i in range(m):
yHat[i] = lwlr(testArr[i], xArr, yArr, k)
return yHat上面代码的作用是,给定\(x\)空间中的任意一点,计算出对应的预测值\(yHat\),函数lwlr()先读入数据并创建所需矩阵,之后创建对角权重矩阵weights,权重矩阵是一个方阵,阶数等于样本点个数m,也就是说,该矩阵为每个样本点初始化了一个权重。接着,算法将遍历数据集,计算每个样本点对应的权重值:随着样本点与待预测点距离的递增,权重将以指数级衰减(即随着\(x^{(i)}\)与\(x\)的差值越大,权重\(w(i,i)\)越小)。输入参数k控制衰减的速度。与上一节的standRegres()一样,在权重矩阵计算完毕后,就可以得到对回归系数ws的一个估计。
另一个函数lwlrTest()用于为数据集中每个点调用lwlr(),这有助于求解k的大小。
最后来看下运行效果:
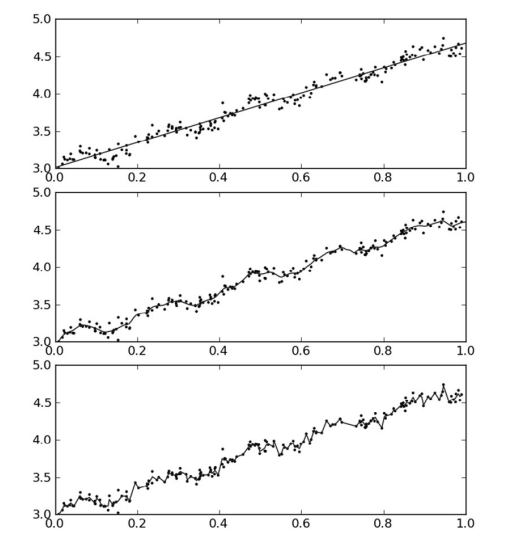
局部加权线性回归也存在一个问题,即增加了计算量,因为它对每个点做预测时都必须使用整个数据集。从图2可以看出,\(k=0.01\)时可以得到很好的估计,同时看一下图1中\(k=0.01\)的情况,就会发现大多数据点的权重都接近零。如果避免这些计算将可以减少程序运行时间,从而缓解因计算量增加带来的问题。
- 参考
- 《机器学习实战》 [美]Peter Harrington著,李锐、李鹏、曲亚东、王斌 译







评论 (0)